
Two things have reminded me that it's been a while since I've written about Stanislaw Burzynski, nearly five months, to be precise. First, on Wednesday evening I'll be heading to the city where Burzynski preys on unsuspecting cancer patients, Houston, TX, to attend this year's Society of Surgical Oncology meeting to imbibe the latest research on—of course!—surgical oncology. (If you'll be attending the meeting, look me up. If you're in Houston and want to have a meetup, I might be able to pull it off.) Second, you, my readers, have been telling me there's something I need to blog about. This time around, my usual petulance at being told I must blog about something notwithstanding, I'm inclined to agree (more later). It is, after all, Stanislaw Burzynski.
The last time I wrote about Burzynski was when McKenzie Lowe, an unfortunate child with a particularly deadly form of brain cancer known as diffuse intrinsic pontine glioma (DIPG) whose parents lobbied to allow her to be treated with his antineoplastons when his clinical trials were still on clinical hold. Ultimately, for reasons that still remain inexplicable, the FDA lifted that partial clinical hold, which allowed Burzynski to continue to treat patients already on his clinical trials but prevented him from enrolling any new patients (or, as I put it, the FDA really caved). In any case, there hasn't been much to blog about since the fall, other than noting that the Texas Medical Board (TMB) is trying to do the right thing by going after Burzynski's license again. There have been a lot of motions and counter-motions, but overall the proceedings have thus far been as exciting as watching paint dry. That s why I haven't had much interest in covering their ebb and flow, particularly given that I'm not a lawyer, nor am I familiar with Texas law with respect to regulating physicians other than that it is hopelessly slanted in favor of protecting bad physicians more than the public. I'm waiting for the big one, the actual main hearing. Until then, I'm trying to keep my pessimism from depressing me about the long odds the TMB has trying to finally bring down Burzynski.
One thing that's not going to help Burzynski, contrary to what he apparently thinks, is the recent publication of the results of Hidaeki Tsuda's clinical trial of antineoplastons in colorectal cancer. Before I discuss the trial, let's just take a moment to explain what antineoplastons (ANPs) are. I realize that most regular readers are familiar with Burzynski and his antineoplastons, but given that it's been so long since I've discussed him I figured a brief recap is in order. The detailed story is contained in an article I wrote for Skeptical Inquirer entitled Stanislaw Burzynski: Four Decades of an Unproven Cancer Cure. The CliffsNotes version follows. Basically, back in the early 1970s, a Polish expat physician named Stanislaw Burzynski, while working at Baylor, thought he had discovered peptides in the blood and urine that inhibited cancer which he dubbed antineoplastons. His evidence wasn't the strongest, but it wasn't outside the realm of possibility that he might have been right. Unfortunately, instead of taking the correct, scientific approach, he bolted Baylor and started treating patients with antineoplastons. By the 1990s, to make a very long, complex story short, he ended up setting up a bunch of clinical trials that were shams, that basically let him administer ANPs as he saw fit. Those were the clinical trials that were put on partial clinical hold and later allowed to proceed, a process detailed in posts showing just how many violations the FDA found in its inspections of the Burzynski Clinic.
In any case, one of the biggest knocks on Burzynski is that he hasn't published complete results of his clinical trials, although, as I have pointed out, he's published unconvincing partial results. If there's one thing, however, that Burzynski apologists like to point out, it's a clinical trial in Japan run by Hidaeki Tsuda of antineoplastons in colon cancer. It's a study that featured prominently in Eric Merola's second propaganda movie about Stanislaw Burzynski. Here's the segment from the film:
Dr. Tsuda explains 27 years of ANP research + randomized study now published from BurzynskiMovie on Vimeo.
I discussed Dr. Tsuda's trial in detail on more than one occasion, most notably in my discussion of Eric Merola's second movie about Stanislaw Burzynski. Hilariously, after the movie, Merola complained about how Tsuda's trial was rejected by Lancet Oncology. Of course, I wasn't surprised by this and, in fact, discussed what likely really happened, which, contrary to Merola's claims, was not that Tsuda's work was being "suppressed." (I also couldn't help but mock Merola for whining about what happens to pretty much every scientist, namely having papers rejected.) Interestingly, another revelation that Merola mentioned was that Tsuda hired a ghostwriter to write the actual manuscript.
So where did Tsuda finally publish his work? Oddly enough, he published it in PLoS ONE. I must admit, I wouldn't have predicted that journal, given that it's not exactly known as a journal that publishes cutting edge clinical trials. In fact, although it might be confirmation bias on my part to say so, every clinical trial I recall seeing published in PLoS ONE has been—shall we say?—not particularly good. This one is no exception.
The first thing that struck me about this clinical trial is that it is a negative clinical trial. As much as Tsuda's group tries to paint it as a positive clinical trial, it is not. Let's just put it this way. The trial failed to find any effect of antineoplastons on overall survival (OS) or relapse-free survival. That's a negative trial in any oncologist's book, regardless of other findings.
But let me back up a bit. Basically, Tsuda's trial is a randomized clinical trial involving 65 patients with histologically confirmed metastatic colorectal cancer to the liver. Liver metastases from colorectal cancer are one of the exceptions to the rule that metastatic disease from solid tumors can't be treated for cure in that resecting liver metastases can result in long term survival. In this trial, all of these patients had undergone resection of their metastases or thermal ablation of the metastases and were enrolled between 1998 and 2004 at Kurume University Hospital. These patients were then randomly assigned to receive either 5-FU (a common chemotherapy drug used to treat colorectal cancer) alone by hepatic artery infusion (HAI, control arm) or to receive 5-FU HAI plus systemic ANP therapy, which included intravenous and oral ANPs. One thing that struck me right off the bat is that infusing chemotherapy, particularly only 5-FU, directly into the hepatic artery is already outdated. Given advancements in chemotherapy for colorectal cancer, intravenous chemotherapy using new regimens can do as well or better than infusing 5-FU directly into the hepatic artery (which requires a surgical procedure to insert a catheter attached to a pump and is thus more risky and less desirable than just intravenous chemotherapy).
A curious aspect of this trial is that the investigators specified that this was based on the "number of metastases and presence/ absence of extra-hepatic metastasis at the time of surgery." To be honest, I'm still not entirely clear what the authors meant by this. Did the investigators choose which group the patient ended up in based on what was found at surgery? Extrahepatic disease (disease outside of the liver) is a bad sign that portends poor prognosis. What I do understand is that the investigators only enrolled patients with an R0 resection, which basically means that after surgery or thermal ablation of liver metastases from colorectal cancer there was no detectable disease left. Thus, at the beginning of the trial, there was no detectable tumor. That was the point and why relapse-free survival was measured.
There are so many problems with this trial. These problems are now much more apparent now that it's been published. Before, I could only speculate because all I had to go on was Eric Merola's biased and oncologically ignorant discussions of the trial designed to promote it as evidence that Burzynski's ANPs are promising antitumor agents. Now, I can look at the published trial results and state unequivocally that I am completely unimpressed, particularly in light of what I know from Eric Merola's films and other claims made by Burzynski supporters. Yes, this is a randomized clinical trial, but it's also an open label, non-blinded randomized phase II study (more on that later). That means that the investigators knew who was and was not receiving the experimental treatment. It found no difference in overall survival between the two groups and no difference in relapse-free survival (time to relapse) between the two groups. Nothing. Nada. Zilch. Again, that's a negative trial. However, it does report a statistically significant difference in cancer-specific survival, with a median survival time of 67 months for the chemotherapy plus ANP group (95%CI 43-not calculated) versus 39 months (95%CI 28-47) (p=0.037) and 5 year CSS rate 60% versus 32% respectively. What does that mean?
At this point, let's review what these various endpoints mean. Overall survival (OS) is fairly straightforward. It just means the time until the patient dies, regardless of cause. It's what I like to call a "hard" endpoint, because it's easy and straightforward. There is no interpretation necessary. A patient is either alive or dead, and investigators know the time from enrollment to the time of death. These are reasons why OS is the "gold standard" for clinical trials testing new cancer drugs. Traditionally, to be approved by the FDA, a cancer drug had to produce a statistically significant improvement in OS. True, as I described discussing the case of Avastin and breast cancer, other measures may be used, but ultimately it comes down to OS. In contrast, relapse-free survival is a measure of the time it takes for cancer to relapse after being seemingly eradicated. In this case, all patients had their cancers eradicated either through surgery to remove their liver metastases or thermal ablation to the point of not having any detectable cancer left; so relapse-free survival in these patients means the time until a detectable cancer relapse is detected, wherever that relapse is.
But what about cancer-specific survival (CSS)? This is a more problematic measure. Basically, according to the SEER Database, it means "probability of surviving cancer in the absence of other causes of death." To get an idea of what CSS means check out Figure 1 in this article comparing and contrasting the various survival measures used for cancer clinical trials. Basically, CSS ignores locoregional recurrence and censors (does not count) non-cancer-related deaths, deaths from other cancer, treatment-related deaths, and patients lost to followup. It also ignores locoregional recurrence (recurrence in the same organ or the regional lymph nodes), new distant metastases, a second primary of the same cancer type, and a second primary of another cancer. In the same article, there is this graph:
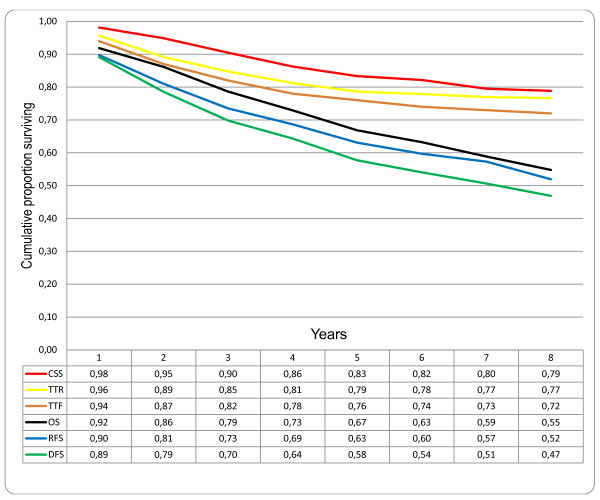 Comparison of different survival endpoints in patients treated with curative intention for colorectal cancer, disease stages I-III (n = 332). CSS: cancer specific survival; TTR: time to recurrence; TTF = time to treatment failure; OS: overall survival; RFS: relapse-free survival; DFS: disease-free survival.
Comparison of different survival endpoints in patients treated with curative intention for colorectal cancer, disease stages I-III (n = 332). CSS: cancer specific survival; TTR: time to recurrence; TTF = time to treatment failure; OS: overall survival; RFS: relapse-free survival; DFS: disease-free survival.Birgisson et al.
BMC Cancer 2011 11:438 doi:10.1186/1471-2407-11-438
Note how CSS produces the highest survival rate, while disease-free and relapse-free survival rates produce the lowest apparent proportion surviving. In any case, CSS has many problems, including:
In this variant, the event is death specifically from the cancer. Deaths from other causes are not "events" and do not cause the curve to decline. Instead, from the time of death forward, a patient who dies from something else is effectively removed from the data. This decreases the number of patients "at risk" from that point forward but does not cause the curve to decline...Disease specific survival has serious problems. Disease Specific Survival ignores deaths which were (or may have been) due to treatment. For a toxic treatment, disease specific survival could be very different from overall survival and it's overall survival that counts in the end. Subtle late effects of treatment can make it hard to even know how toxic the treatment actually was, a problem which doesn't arise when the endpoint is plain survival. Disease specific survival is also known as Cause Specific Survival.
Another problem with CSS is that it is prone to misclassification of cancer-specific deaths, resulting in biased estimates of CSS. In other words, an explicit decision has to be made as to whether a given death observed was due to the cancer. Some deaths will be clearly related to the cancer. In others, the cancer might be a contributory, but not main, factor in the death. This might not be a major problem if the trial were blinded, but the trial was not blinded. The investigators knew who was in each group. It's impossible to rule out subtle biases leading to the classification of more deaths of patients in the control group as being cancer-specific than in the ANP group. Indeed, it's hard not to suspect that this is exactly what happened, given not even the whiff of a hint of a statistically significant difference between the ANP and control groups in other endpoints, such as OS and RFS. It's also hard not to suspect that CSS was not a primary endpoint for the original trial but was added on, post hoc, when it became clear that the differences in OS and RFS were not going to be statistically significantly different. There's no way of knowing, unfortunately, because the trial was not registered from its outset, but rather in 2013. (In fairness, it wasn't required to be when it started; the law requiring clinical trial registration came years later.)
Another interesting aspect of this trial is that I now know who is the ghostwriter for Tsuda's trial. It's Dr. Malcolm Kendrick, author of The Great Cholesterol Con, which is not a promising start. In any case, Kendrick declares publication of the Tsuda paper as a "victory":
I was then contacted by someone, who shall currently remain nameless, who told me that a group of Japanese researchers had done work on antineoplastons as adjuvant (add-one) therapy for patients with liver metastases following colorectal cancer. They did not know how, or where, to publish it. So I agreed to look at it, and try and get it published in a peer-reviewed journal.
They were turned down by Lancet Oncology (no surprise), and a couple of other journals. I suggested PLOS (Public Library of Science), which has a high impact and tends to be a bit more open to non-mainstream articles. So we sat down to write, rewrite, edit, alter and adapt.
To be honest, I have never, ever come across so many objections by the peer reviewers. Stuff that was so trivial, so difficult to answer. Re-write, re-write, re-write. Water down the conclusions. I thought by the end of it, nothing would be left, although the most important points did, just about, survive.
Again, as I discussed above, PLoS ONE isn't really well-equipped to publish clinical trials. Even so, apparently those peer reviewers saw through the hype in the original manuscript immediately (assuming that the first version submitted read anything like what was described by Eric Merola). Good. Interestingly, Adam Jacobs, a UK statistician, comments. Like me, he notes that the primary endpoint (CSS) is an unusual one to use. (It's worth repeating that CSS is almost never—strike that, never—used as an endpoint in trials intended to be used in applications for FDA approval, for the reasons I've discussed above.) He also notes:
Third, and perhaps most importantly (especially in light of my first point), there was no mention of allocation concealment. Do you know if the investigators had access to the randomisation list when recruiting patients? I’m sure I don’t need to explain to you how that would completely invalidate the results of the study if they did.
Yep. Allocation concealment is a procedure that is done in randomized trials to make sure investigators are not aware of what experimental group the patient will be assigned to; i.e., procedures to make sure that neither patients or investigators know what group a given subject will be assigned to. As the World Health Organization (WHO) notes, without allocation concealment, "even properly developed random allocation sequences can be subverted, going on to write:
Within this concealment process, the crucial unbiased nature of randomised controlled trials collides with their most vexing implementation problems. Proper allocation concealment frequently frustrates clinical inclinations, which annoys those who do the trials. Randomised controlled trials are anathema to clinicians. Many involved with trials will be tempted to decipher assignments, which subverts randomisation. For some implementing a trial, deciphering the allocation scheme might frequently become too great an intellectual challenge to resist. Whether their motives indicate innocent or pernicious intents, such tampering undermines the validity of a trial. Indeed, inadequate allocation concealment leads to exaggerated estimates of treatment effect, on average, but with scope for bias in either direction. Trial investigators will be crafty in any potential efforts to decipher the allocation sequence, so trial designers must be just as clever in their design efforts to prevent deciphering.
The methods section of the paper indicates:
Randomization used 50:50 weighting to the two arms and was established by computed macro program in Microsoft Excel 97 (Microsoft Cooperation, Redmond, USA).
Excel? Seriously? Also, how was randomization determined? If anyone had access to the list of assignments beforehand, the process could have been subverted. (See Adam Jacobs' comments in the comment section below.) Not to diss Excel (too much) as it's not that horrible a random number generator, but a spreadsheet is not a particularly secure method of determining subject allocation to different arms of the clinical trial.
Here's an even bigger problem. The trial was also open label, which means it was completely unblinded. The doctors treating the subjects and the researchers analyzing the subjects' scans (not to mention determining whether a death was due to cancer or another cause) potentially knew which group each subject was in. Knowing the treatment group could easily subtly (or not-so-subtly) influence determinations of whether a death was cancer-related or due to another cause. That's why, at the very minimum, the investigators determining if relapse had occurred or if a death is related to the subjects' original cancer or to a different cause. These determinations are not always straightforward. Jacobs is right to emphasize this. Unfortunately, in response to Jacobs' questions, Kendrick's answers were—shall we say?—not at all reassuring. In fact, I think Kendrick was downright evasive. For example, even though he bragged about writing the manuscript, whenever questioned about matters like these, Kendrick told Jacobs to contact the investigators. To characterize such a response as "lame" is being generous. Elsewhere, he says things like:
To be frank, I also know that whatever questions are answered, Adam Jacobs (and many others) will always believe it was fraudulent. Any question answered will be followed by another question, and another question, ad infinitum. At some point, as with any trial, there will be imperfections. I know from past experience, that if I make the slightest error, this is leapt upon and used to discredit everything I have to say, on any matter. I spent a year trying to sort out detailed questions about this study. I really, really, do not want to spend another year doing so. Especially when it will make not the slightest difference. Those who disbelieve this study will continue to do so. No matter what. It is the nature of the thing. Please do not confuse weariness with evasiveness – or any other motivation that you may feel is lurking beneath the surface here. Just because someone demands that I answer questions does not mean that I have to do so.
In retrospect I made a tactical error. I should have just said. If you have detailed questions please contact the lead author, or direct questions through the journal. End of.
Funny, for someone who claims to have spend a year editing the paper and "trying to sort out detailed questions about this study," Kendrick is quick to claim ignorance about a very basic and appropriate question asked by Adam Jacobs. How on earth could he have written the manuscript and not known the answer to this very, very basic question? Is he incompetent? I say yes. And I am not "confusing weariness with evasiveness." I'm correctly calling out evasiveness.
Meanwhile, Eric Merola is making excuses on Facebook in this hilarious post:
Particularly hilarious to me is the claim by Merola that "the Japanese were forced to 'water down' and 'downplay' the significance of the studies in exchange for allowing it to be published by the team of oncology peer-reviewers at PLoS ONE (Public Library of Sciences)." Damn those peer reviewers and their pesky insistence on proper statistics! My only thought was, "Dude, welcome to the real world of science! That's how it's done! Peer reviewers, when they are doing their job, force authors to stick to only conclusions that can be supported by the data. Having published in PLoS ONE myself a couple of times, I also understand the process a bit from the author's perspective. Basically, PLoS ONE is very particular about enforcing the journal's standard that, yes, it will publish pretty much anything (even negative studies) as long as the conclusions are reasonably supported by the science. The moment you go beyond what can be rigorously supported by the evidence in your conclusions and discussion is when the reviewers will stomp on you. I learned that the hard way, and now, apparently, so have Tsuda and Kendrick. Good.
Even more amusing is Merola's further whine:
PLoS ONE might catch some heat for doing the "right thing" here, they reviewed this manuscript and kept watering it down for over a YEAR before accepting it for publication. The Japanese were forced to say things like "Overall survival was not statistically improved" even though the survival was DOUBLE in the Antineoplastons group. They also had to say "Antineoplastons (A10 Injection and AS2-1) might be useful" - instead of "Is useful", etc. Baby steps, we guess.
Seldom have I seen such ignorance. OS was not "doubled" if the difference was not statistically significantly different. That's the definition of "statistically improved," and Tsuda's trial didn't achieve it. As for having the authors say that ANPs "might be useful," I'd actually say that the reviewers were too easy on Tsuda and Kendrick. The very data presented show that ANPs are not useful as an adjuvant therapy for successfully resected colorectal cancer metastases. Again, this is a negative trial. Indeed, the paper notes that three patients died in the ANP arm from other causes: from pneumonia, from myocardial infarction, from an accidental death. These were not counted in CSS, and it wouldn't surprise me in the least if they were the reason why OS was not statistically significantly different between the groups, particularly given that the difference in CSS wasn't impressively different, at least in terms of the p-value (p=0.037).
Poor Mr. Merola. Poor Dr. Kendrick. Poor Dr. Tsuda. They hitched their wagon to Stanislaw Burzynski's ANPs. Now they can't unhitch it. Embarrassment is theirs, as well it should be.
The "Author Contributions" section states
If this is untrue, and the paper was in fact written by Kendrick, I scent a retraction on the way.
Interesting point...
He didn't write it. He did edit.
Is this common in the real world?
Adam Jacobs (and many others) will always believe it was fraudulent.
I only read the comment Orac linked to in the original post, but where does Adam Jacobs claim the study was fraudulent? He does say that the CSS metric appears to have been chosen post hoc. But that's "torturing the data until it confesses", not fabricating the data. And even after they have done it (assuming they have done it correctly, a point I am not qualified to evaluate), they get a result that is only statistically significant by a narrow margin. The 95% confidence intervals on survival times overlap, even if only by a few months. And a p-value of 0.037 is still high enough that this apparent positive might well be spurious--there is a reason (beyond the fact that they can) that physicists often insist on 5σ significance, rather than the 2σ level which roughly corresponds to p=0.05, to consider a result positive. So while there may be questionable things about this paper, I don't see any evidence so far to support a fraud charge.
Great analysis, David, but the allocation concealment problem is, I think, even worse than you have made it out to be.
What you have described is the limitations that come from the study not being blinded. They may not matter too much for overall survival (which was negative), but as you rightly point out, they matter a lot for endpoints like CSS and PFS.
But the problem of allocation concealment is subtly different. That's about whether, when faced with a patient whom the investigators might or might not choose to enrol in the trial, they can know in advance which treatment group the patient would be in if that patient is indeed recruited.
And that is in many ways a more serious problem.
Imagine if you are faced with a patient who is very ill and you suspect has a particularly poor prognosis. It's not beyond the bounds of possibility that you would be more likely to make the decision to enrol that patient if you knew that the next treatment on the randomisation list was the control group than if it was the ANP group.
So allocation concealment is not the same thing as blinding. You will always have good allocation concealment in a properly double-blinded study, but you will only have good allocation concealment in an open-label study if you take proper precautions to make sure the investigators don't know what the randomisation list looks like until each patient has been definitively recruited. There's nothing here that tells us that allocation concealment was achieved.
So in other words, if there was no allocation concealment, then not only was the study not blinded, it wasn't even properly randomised.
Actually, this is an open label study. It's not even blinded. Which is OK for a hard endpoint like OS, but definitely not OK for RFS and CSS, both of which are judgment calls, CSS more than RFS.
If methodological problems with a study are so big that even a brorderline scientifically illiterate person, such as me, could point to them (well, some of them at least) it means the study is pretty bad.
I decided to alter the discussion about allocation assignment somewhat because Adam is correct that I came too close to conflating proper blinding and allocation assignment. Also, the study is unblinded; so discussing blinding in such detail is unnecessary.
A young rapscallion has a response to his letter in Nature.
The role of academic health centres to inform evidence-based integrative oncology practice REPLY
http://www.nature.com/nrc/journal/v15/n4/full/nrc3822-c4.html
The role of academic health centres to inform evidence-based integrative oncology practice CORRESPONDENCE Published online 24 March 2015
http://www.nature.com/nrc/journal/v15/n4/full/nrc3822-c3.html
Forgive me if I am late to the discussion, my wife always compliments me for my lateness and accuracy.
After reading the Nature opinion letters linked in comment #10 (thank you Dr. Johnson), I do have one minor quibble with one aspect of Dr. Gorski's reply. He states: "Combine equivocal (at best) clinical trial evidence regarding acupuncture with its extreme biological implausibility, and the most parsimonious explanation for the reported effects of acupuncture remains that it is a theatrical placebo, regardless of reported functional MRI findings."
I think the functional MRI findings are significant and should not be discarded as irrelevant. Given that acupuncture has not been shown to work at greater levels than placebo, I put forward as a hypothesis that the acupuncture functional MRI results should be examined as mechanism of action for the *placebo effect* in pain relief. If people are fooling themselves into thinking they have less pain through their imagiantions, then a similar functional MRI should result from other similarly ineffective 'alternative medicine' scams causing pain relief placebo effects. The sCAMsters might have hit upon some real science, just not in a way that supports their delusions.
After reading the Nature opinion letters linked in comment #10 (thank you Dr. Johnson), I do have one minor quibble with one aspect of Dr. Gorski's reply. He states: "Combine equivocal (at best) clinical trial evidence regarding acupuncture with its extreme biological implausibility, and the most parsimonious explanation for the reported effects of acupuncture remains that it is a theatrical placebo, regardless of reported functional MRI findings."
I think the functional MRI findings are significant and should not be discarded as irrelevant. Given that acupuncture has not been shown to work at greater levels than placebo, I put forward as a hypothesis that the acupuncture functional MRI results should be examined as mechanism of action for the *placebo effect* in pain relief. If people are fooling themselves into thinking they have less pain through their active imaginations, then a similar functional MRI should result from other ineffective 'alternative medicine' scams causing pain relief placebo effects. The sCAMsters might have hit upon some real science, just not in a way that supports their delusions.
@Dr. Johnson and JerryA: Your comments are way off-topic for this post. (Particularly you, JerryA, posting three identical copies of the same post so that I had to delete two of them.) Stop it.
My apologies for both the off-topic comment and multiple identical comments posted. The multiple posts were not intentional.
I probably wouldn't have been so annoyed if not for all the duplicates.
Someone has mentioned a phase 3 trial of antineoplastons. Should be interesting.
"This one is no exception. PLoS ONE"
I see what you did there : )
I was initially really skeptical about PLoS One, but I have to say it has become much more prestigious than I ever thought it would. A mixed bag for sure, but some good papers there.
If AS2.1 and A10 are, as claimed, Histone De-acetylase Inhibitors (HDACi), it would unsurprising to see at least some improvement in recurrence free survival. Just like thousands of other drugs, it's not enough to be effective... you have to be more effective and well-tolerated than current therapeutic options. How, for example, does AS2.1 compare to Vorinostat? Anyone know?
Gosh, it's amazing that this is the first real trial in so long, considering how many trials Burzynski has opened and chosen never to conclude or publish. It's almost as though he had a business model that allowed him to exploit the research trial system to make massive profits. Would that make him the most beloved millionaire Pharma CEO in history?
I don’t do clinical research, so I’m asking very honestly: is this something that actually happens? Researchers design and execute a trial in human subjects, THEN try to figure out how to navigate the publication process?
Perhaps the group just didn’t know how to force a weak study into publication?
Excellent comments, except for your criticism of the Texas Medical Board. If you do your research, you will find that they are very aggressive at going after even minor infractions, to the point where they are heavily criticized for being draconian in the handling of stuff like not documenting your CME well enough. Unfortunately, once it goes into the legal system, the lawyers can drag stuff like this out forever, and evidently Burzynski has high dollar lawyers.
The example of Stanislaw Burzynski, and two other big examples I'm aware of, would argue otherwise, not to mention the article I cited about how much the law in Texas is stacked against the TMB in terms of stripping bad doctors of their medical licenses.
This was a nice touch:
I mean, they're expired, but he owns them, dammit!
I'm entirely unqualified to do this, but naively applying Colquoun's approach to false-discovery rates, I'm getting FDR = 20% for P(real) = 0.5 and FDR = 69% for P(real) = 0.1.
Everything about this paper/trial is bizarre.
Dr. Malcolm Kendrick says that the Japanese researchers didn't know "how or where" to publish the results of their trial. Really? have they never read a paper before? I just find it unlikely that a whole team of researchers who are capable of putting together a (not good) clinical trial have *no idea* of what journals are out there where they might publish their results.
I use Excel for randomization for little lab experiments, but for a clinical trial? Uh, no. Don't you at least have STATA?
I can understand not wanting to have OS as your only metric, if only because it can take a really long time to collect enough data, and that can be frustrating/problematic for trials with limited funds. But you've got to pick something better than CSS, which looks like "how to make your data look the best!"
It's really weird.
@ CTGeneGuy
I don't do clinical research, so my input could be of limited value, but it did happen to a few of the research projects I was involved with to first be completed, and then we started talking about which journal we could try to submit the results to.
That being said, the discussions were on the lines of "we did manage to publish in journal X before, let's do it again" or "this article from the renowned Dr Smith has been instrumental in our project, let's try to publish in the same journal".
Or simply "Journal Y is still in the upper tier in our field?" " Yeah" "Do you think our work is good enough?" "Um, yeah" "Let's go for it".
I have to admit, the bit about a scientific team not having a clue where to publish and needing an outsider's advice sounds amateurish, to say the least.
They were turned down by Lancet Oncology (no surprise), and a couple of other journals.
I think this, plus a bit of language barrier, is why Dr. Tsuda's group "did not know how, or where, to publish it." There is no shame in aiming high and failing in your first attempt to publish a paper. But according to Dr. Kendrick, this paper was already a three-time loser by the time he was brought in. That tells me there was something seriously wrong with this paper--I've had papers rejected before for trivial reasons and then accepted at another journal, but when this happens multiple times, it's more likely that the referees agree that this paper isn't up to snuff--and not just with English usage, as there are professionals out there who will edit papers to bring the English up to snuff. Kendrick basically admits as much when he says that he hadn't seen so much pushback from the referees at PLoS ONE. I think it's more that Tsuda got lucky with referee roulette at PLoS ONE, in that he got referees who were willing to recommend major changes rather than outright rejection. (This is one reason I occasionally see papers where my reaction is, "How the #&*@ did this get past the referees?") So Tsuda and his colleagues complied with the referee's suggestions, to the best of their ability, and the editor accepted the paper.
I know a little about pseudo- and true- random number generation, albeit when applied to ciper use. I truly, truly would not advise anyone to use Excel to give them a serious random component. Even the somewhat farcical PuttyGen 'squiggle the mouse' method is an improvement, a considerable improvement.
I am genuinely astonished they would even think about using Excel for this. Surely there were funds to build a hardware true random number generator? You can solder a pretty good one together from bits in the Maplins catalogue for less than £30... Or even the RS catalogue if you insist! Surely they had access to at least one electronics engineering undergraduate??? I mean, most of us would have done it just for the attention!
Jesus H God-dancing Christ...!!! An Excel visual basic for applications macro... That's a good one.
I'm missing the part where the quality of the Excel PNG per se isn't a red herring. The description provided, which is opaque to me, reads in full,
"Eligible patients were randomly assigned to receive systemic antineoplastons plus 5-FU HAI (AN arm) or 5-FU HAI alone (control arm) by a minimization method using number of metastases (1–3 vs ≥4) and presence or absence of prior extra-hepatic metastases which were removed completely (R0 resection) at the time of surgery. Randomization used 50:50 weighting to the two arms and was established by computed macro program in Microsoft Excel 97 (Microsoft Cooperation, Redmond, USA)."
They obviously needed roughly equal numbers in each group, which rules out simple coin-tossing for N = 57, and they needed to account for two other variables.
If someone familiar with actual study design could point me in the direction of a clue, it would be much appreciated, but naively, it seems as though the details of the algorithm would be the point of interest.
Its just... Hugely amateur.
I suppose they didn't absolutely NEED truly random numbers. Nonetheless it doesn't in my opinion reflect well on the professionalism of the rest of the project. Moreover given how flawed, or just outright absent the blinding was then any true entropy during their selection process becomes all the more valuable. Instead they used a visual basic routine and a number-sequence... Horrible.
My vague understanding of "minimization method" is: the pool of patients was divided into 4 sub-groups then each subgroup was randomly divided 50-50? Perhaps those subgroups were thus small enough that the crappy choice of randomizer was unlikely to have much impact... particularly given the other HUGE GAPING FLAWS? Seriously, I have never designed a study, never really learned how to, but even I can see how they completely opened themselves up to reporting bias.
(subgroups being: a. 1-3 no r0, b. 4+ no r0, c. 1-3 yes r0, d. 4+ yes r0, each needing to be divided evenly, do I have that right?)
For one-off purposes, there's no shortage of transcriptions of numbers-stations transmissions that aren't Cuban. Then again... Venona!!1!
But seriously, the number of substrings with equal numbers of 0's and 1's for n total digits is the number of pair swaps necessary to count from all 0's to all 1's. The number of strings obviously grows as 2ⁿ, but this has a certain O(n lg n) feel to it. (I'm too lazy to find the correct answer.)
One could probably just enumerate them all and pick one out a hat.
^ Or I could not be an idiot and observe that it's n choose n/2.
^^ And the whole digit-swaps thing is complete horsesh*t, sorry.
@CTGeneGuy:
"I don’t do clinical research, so I’m asking very honestly: is this something that actually happens? Researchers design and execute a trial in human subjects, THEN try to figure out how to navigate the publication process?"
Yes, it happens far more often than you think. And I speak as someone who spent 15 years running a company providing clinical research consultancy services, one of which was helping researchers figure out how to publish their results.
There were probably 2 things that made it hard for these researchers to get published:
1. The language barrier
2. The appallingly bad design of the study, which would have meant that any respectable journal would have not felt it worth publishing
@Narad:
"I’m missing the part where the quality of the Excel PNG per se isn’t a red herring."
Yes, I think you're right about that. Using Excel in a clinical trial certainly smacks of amateurism (I have worked on many randomised trials over the years, and I have never once come across a randomisation list that was generated with Excel), but actually, as long as you do everything else properly, there's no real reason why you shouldn't use it.
The problem here is they didn't do everything else properly. Really, really, far from it.
For those concerned about the fact that Excel only generates pseudorandom numbers and not true random numbers, that's true, but that's also true of pretty much all the tools that the best researchers use for random number generation. If you used Stata or SAS for your randomisation list, you would still get pseudorandom numbers. Maybe Stata and SAS have better pseudorandom number generation algorithms than Excel: I don't know. But I don't think that's really the point.
The point is this. If you are the investigator in the study, and a patient walks through the door of your clinic, do you know which treatment that patient would get if you enrolled that patient into the study?
That's the only question that matters.
Now, let's suppose the investigator knew which treatment the previous patients had received. In this case, that's almost certainly true, because this is a single-centre study. In a multicentre study, you wouldn't necessarily know what patients in other hospitals had had, but if all patients are treated in the same place, you do.
The randomisation algorithm only has to be unpredictable enough that the investigator couldn't predict what the next treatment would be from knowing the previous ones. I'm pretty sure Excel would be good enough for that.
But, and here is the real fatal flaw in this study, all this assumes that the entire randomisation list isn't sitting on the investigator's desk right in front of him at the time. If the whole list is in front of his nose, then of course he knows what treatment the next patient will receive. There is nothing in the paper to state the the randomisation list was concealed, and given the amateurish way it was done (this is probably the most important thing the use of Excel tells us), I strongly suspect that entire randomisation list was known to the investigators in advance.
Now, then you're talking really weapons-grade design flaws.
If the investigator knows which treatment the next patient will receive, then the potential for bias becomes huge. Suppose the next treatment on the list is ANP. The patient who walks through your door is very seriously ill, and you don't expect that patient to last all that long. You don't really want patients like that in the ANP group, as it might make ANP look bad. So you tell that patient to come back next week and maybe you'll talk about the trial then. In the meantime, a much healthier patient walks in, who gets cheerfully enrolled in the study, and assigned completely not at random to the ANP group. The sick patient comes back next week, by which time the next treatment on the list is the control group, and then gets recruited into the study.
Repeat that 65 times and you could end up with seriously unbalanced treatment groups.
And yet they still couldn't show a significant advantage of ANP!
There's a further problem with the randomisation. If you look at the links to supplementary material, you can download the protocol. Now, one rather fishy thing about the protocol is that protocols are supposed to be written before you start the study. The protocol here includes the information that patients were recruited between April 1998 and August 2004. Pretty fishy given that the protocol is dated February 2003, don't you think? OK, protocols sometimes get amended after the trial starts, and sometimes for perfectly legitimate reasons, but there really ought to be a transparent description of what changed and why. We are told nothing about that.
But that aside (though we really shouldn't put it aside, because it's extremely serious), the description of the randomisation method in the protocol is completely different to what is described in the paper.
The protocol says that the treatment assignment was done using minimisation, not randomisation. For such a huge discrepancy to exist between the protocol and the paper is pretty serious stuff.
Now, minimisation is a perfectly reasonable alternative to randomisation in some circumstances. It all comes down to whether the investigator can know the next treatment before a patient is enrolled. But because minimisation has an element of predictability, it is never suitable for single centre studies. It can only be sufficiently unpredictable if you have a multicentre study where you don't know what treatment patients in other centres got.
So really, one way or another, there is something extremely worrying about the randomisation method here. I would go so far as to say that this wasn't really a randomised trial at all.
...which is why many modern trials use permuted block randomization within each stratum.
You know, now that you mention it, if this did happen, then it suggests that the ANP patients probably did worse enough to eliminate the expected difference in outcomes between the ANP+HA chemo and HA chemo alone groups. If your educated speculation is true, it really makes one wonder if ANP actually harmed patients.
@Orac - that is an interesting supposition, given the serious side-effects that come with using ANP....as has been evidenced by the public patient experiences shown over at TOBPG.
One thing I like to point out is this. Our speculations are based on what is in the paper and our knowledge of clinical trials and, at least to me, do not constitute a charge of scientific fraud. They do, if true, however, constitute a charge of scientific incompetence.
Ignorant question by a non-scientist, but wouldn't the definition of "cancer-specific survival" exclude deaths caused by ANPs themselves? We know they killed at least one patient, and if sicker patients in the ANP branch were more likely to die of the ANPs, that would raise CSS without lowering OS (since equally sick patients in the control branch would also die, but of the cancer).
Correct. That is one of the problems with CSS. It excludes deaths due to treatment toxicity.
"We know they killed at least one patient" -- not in this trial of course.
You know what I find interesting, how well what I was taught about clinical trial design comes out in studies like this and TACT. If you have a poorly done clinical trial, with a lot of what I would term "protocol squishiness" (note this is different from an a priori pragmatic design), what would one expect to see? One could expect a marginally significant main result (very likely spurious) and a more pronounced result in subgroup or secondary analyses (likely due to protocol variations which are more impactful in such a group).
What do we see here? and in TACT? That's right, exactly this phenomenon.
Yes, I had seen that before I got distracted by finding substrings generally [n choose k turns out to be Θ(nᵏ), but it's not necessary to enumerate them all to construct a single entry, which is just any ordered sequence of k elements of {1, 2, . . . , n}].
^ For k = n/2, that is.
Let's see if I've got this straight ...
If I feed sugar pills to the control group and sugar pills to the homeopathy group, and then shoot half the homeopathy group dead, I've practically ensured that the homeopathy group has better CSS than the controls?
Wow Adam Jacobs, that is significant if the protocol was written after treatment started and specified a different randomization than was stated in the paper. I agree as well, if they were up to shenanigans and they still couldn't improve survival at all then ANPs must be worse than we thought. Which is hard to believe. The CSS analysis seems ad hoc, added at the end so that they had something to say was positive to their supporters. What is even sadder is that the supporters will believe it.
It would seem so. You could accomplish the same thing by feeding the homeopathy group Conium Maculatum .001X.
Orac (#37):
"If your educated speculation is true, it really makes one wonder if ANP actually harmed patients."
Indeed. Though of course it is just speculation. There is certainly a potential for extremely biased treatment assignment. If the investigators acted dishonestly, then treatment assignment would have been very biased, and if so, it's quite likely that ANP was actively harmful. However, we don't know that the investigators acted dishonestly. Having said that, even if they acted honestly, subconscious biases might have influenced the treatment assignment. But if they were honest and good at controlling their subconscious urges, then it could have been a fair allocation of treatment (though I note from table 1 of the paper that control patients had had longer since original surgery, suggesting they were further along in the course of their disease).
And even if it was fair, of course, there's still the inescapable fact that there was no significant effect on overall survival.
The operation was a success!!!!...........Unfortunately,.. the patient died.
Andreas Johansson@46:
You should apply for a job at NCCAM, mate. They could really use the help getting positive results for a change.
Hi, nice post, thanks!
Just one point to make though. You say 'The very data presented show that ANPs are not useful as an adjuvant therapy for successfully resected colorectal cancer metastases'.
Not wanting in any way to lend support a process that is outside of proper scientific medicine (you know who etc. etc.), but, but:
You cannot use failure to reject the null to support the null hypothesis. You failed to reject the null is all. No more. At least in the frequentist framework. This isn't evidence they 'antineoplastons' don't work. Even if it were a proper trial of a nice big size, and it were negative, you still logically can't support the null. Reason being that there are essentially infinite other models you could have also failed to reject. Sad and frustrating, but that is how, in some sense, hypothesis testing is a bit of a let down.
Ugh. Pedantry.
I know all that. On this this blog (and elsewhere) I emphasize science-based medicine, which is Bayesian, not frequentist. Given what we know about the biology of ANPs, previous clinical trials, and Burzynski's history, it is entirely appropriate to simplify the whole frequentist discussion, turn it into a more Bayesian angle (not to mention aim it at lay people) and say that Tsuda's study is evidence that ANPs are not useful in this context.
There's also sarcasm. Did you not detect the sarcasm in the title and in that statement to which you object on frequentist grounds? It's there to tweak Burzynski and his propagandists.
So should a professionals for ex. oncologists then completely dismiss current research regarding ANPs as possible treatment of specific cancers, or should they build on this research until a more modern and scientific verification has been introduced?
15009212
JJ: No, they should not "dismiss current research", since it shows that ANP chemo is almost certainly a waste of time and a danger to the patient; neither should they "build on this research", for essentially the same reasons.
I am unable to post this in the Success Stories for whatever reason,so
I posted here. I was diagnosed with prostate cancer on October 20,
2012. I was advised by my doctor that my only options were to get a
prostatectomy or have radiation seeds implanted in my prostate or
receive regular external beam radiation. I declined. I knew there had
to be other options.
I scoured the Internet and discovered a wealth of information about
cannabis oil curing cancer. I was able to obtain some medical marijuana
oil Dr Max Gerson (Rick Simpson Oil) from it and consumed the
recommended dosage by mid January.
On January 26th 2014 I had a cancer reassessment which consisted of an
MRI with a state of the art Tesla 3 MRI machine. Results – NO SIGN OF
CANCER! CANCER FREE!
One of the things that helped me while going through all this was
reading the testimonials and the success stories of those who have used
the oil and were cured And with good food diet. Now that this wonderful
oil has cured me, I feel I need to let others know as well. Please feel
free to contact me, ask anything should you like more information or
directly contact Dr Max Gerson at: Drmaxgersonmedicalhome@gmail.com
were i purchased from.
Thank you.
Kind regards,
Claire Murray.