
Its hardly an original question. And the answer (we don't know) isn't original either. In case you were wondering, this is Overland and Wang, GRL 2013, doi: 10.1002/grl.50316 (PDF courtesy of V). Different but not entirely different to A sea ice free summer Arctic within 30 years?, also in GRL; or even A sea ice free summer Arctic within 30 years-an update from CMIP5 models by Wang and Overland.
W+O discuss three methods for predicting future Arctic sea ice: extrapolation, wild guesswork, and cherrypicking your favourite model (of course they don't use those names, they've made up some fancier ones, but it comes to the same thing).
Extrapolation is to be done from ice volume, not ice extent. No expense is spared to fully justify this important choice: Their main points are that sea ice volume is decreasing at a rate that is
faster than sea ice extent, and that volume is a better variable than extent to use for sea ice loss. Well, you can't argue with that, so I won't try to.
Wild guesswork is the idea that ice loss occurs primarily through big loss years like 2007 and 2012, so we sort-of think of a trend, and then guess that things like 2007 or 2012 might happen, errm, sometimes.
Cherrypicking your favourite model is when you look at the sea ice observations (oddly, at this point you silently switch back to extent from volume, but since you do this silently you don't have to explain why) plotted on top of spaghetti diagrams from CMIP and realise that you can make nothing of them. So perhaps you should throw the slower ones away.
These three different methods produce completely different answers, and so you end up concluding that you know nothing.
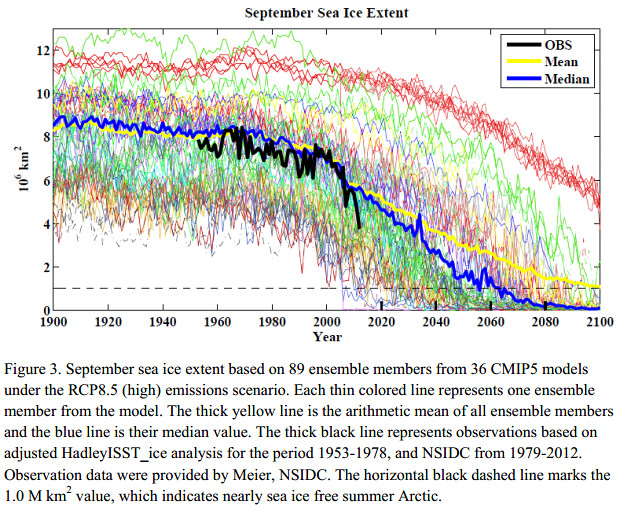
How might we do things better? Weeeeeellll, I'm not in the game anymore, so I can have fun. The O+W approach reminds me of Lord Dorwin, the aristocrat in Foundation whose idea of research is only to re-read the works of others. I've always thought (though I may not have said it very loudly, so please don't challenge me to find me saying it somewhere) that plotting all the CMIP models is silly: some of them aren't very good (I have a paper sort-of saying this: An Antarctic assessment of IPCC AR4 coupled models). Fig 3, reproduced above, needs to have the goo-n-dribble models removed (ah yes, cherrypicking: but no, it needs to be done on some objective grounds; see my paper). The most obvious thing about fig 3 isn't that the obs disagree with the models, but that the spread in the models is enormous. But even with the junk removed I fear you'd find the obs retreat faster than the models; and I'm beginning to wear thin the idea that this is just a few years anomaly. So, really, we need better models and a better understanding of what is going wrong with the current models. That won't come from spaghetti graphs or equation-free papers, though.
Late last year a recent Oceanographer of the Navy, RAdm. Titley, said he expected some ice free weeks at the North Pole two or three decades hence.
Interesting that Titley doesn't seem to have been listening to his own sea ice modeler. OTOH it's become clear that nearly all scientists are very hesitant to make near-term climate predictions/projections that have major implications. A date well after the likely terminal date of one's active career is ever so much safer. Given that, one might interpret the seemingly near-consensus projection of around 30 years as meaning "the soonest we're willing to say in public."
Of course our host, unconstrained by career concerns, is free to boldly go where others fear to tread.
Soot.
Is it desirable to reject models that have done poorly up until now, and only have an ensemble of models that have been at least approximately correct in the past?
[Broadly, yes. But you need to be somewhat cautious about how you do it -W]
It's been very cold east of Novaya Zemlya this winter -- expect the ice there to cling on til August. Give you something to avoid talking about.
... I mean the Kara Sea, specifically.
Aidan --- That is considered to be less desirable than to use a form of Bayesian reasoning to weight the results of all the models by the degree of perfomance to date.
Willy, by now the thirst must be affecting your brain.
We have beer for that.
Needs water to make last time I checked. Plus it's less than ideal for showering.
Re the Kara, it and the other peripheral sea will melt regardless (although once upon a time that wasn't so true). All eyes will be on the Central Basin, which as we speak is cracking to flinders and flushing out the Fram at a breakneck pace. Don't forget the popcorn.
Aidan, the difficulty is that while there are a few clearly crap models that are kept in the IPCC ensemble for political reasons (national pride mainly), the rest don't tend to have consistent strengths and weaknesses. That said, papers that pick out a subset of better models (based on a specified criterion) seem to be getting more common. Also, a couple years ago there was a proposal by Knutti (co-author Mahlstein IIRC) that the best criterion to use is Arctic amplification, and that a good proxy for that is Laptev Sea sea ice cover. I think only about half the models did reasonably, and just a few did what might be called well (albeit still falling short).
The interesting thing about that graph is that the primary difference is the estimate of ice extent in 1900. The trends are all pretty much the same, a bunch of parallel line
Whether the actual date is 2040 or 2100, the point is that it is happening.
To follow up on Eli's point: I am pretty sure I've seen (though I cannot now find) a graph that showed Arctic sea ice loss projections normalized by degree global temperature change and there was much more agreement between the models than seen in Figure3 in this post...
[Oh, I see what you mean. That would be an interesting way of removing a part of the bias and variation. I still think that a lot would remain, though -W]
>"Arctic sea ice loss projections normalized by degree global temperature change"
Would it be better to normalize by 'degree global temperature change * arctic amplification factor' ?
Alternately/additionally: move graphs up or down to match start date observations and scale rate of change for a best fit. Trouble with this is do you use a period 2006-2012 which will give confident prediction of about 2020 or a longer period which gives more uncertainty? OK, that 'bias correction' is a bit rubbish.
Still some attempt at bias correction seems better than none doesn't it?
What percent chance of under 1m km^2 extent occurring by 2020 would be your best guess?
How large would that percent chance have to be to cause a conclusion that serious consideration should be given to potential consequences of a seasonally ice free arctic?
Here are some "predictions" from the scientists among the panelists at The Arctic Summit last week:
Stefan Rahmstorf - 2040
Ellen Baum - 2027
Jan-Gunnar Winther - 2023-2033
Rear Admiral Jonathan White - 2023
Do all of these models replicate the atmospheric blocking patterns that seem to be at the root of the increase in extreme weather? I'm not sure how well this can be quantified, but if it can, then it would be interesting to see a comparison of those that can versus those that can't.
AIUI, Kevin, the models show blocks just fine, but have fallen down on the recent changes. Probably it's best to see that as an aspect of the more general failure to replicate the pace of Arctic amplification.
I predict arctic largely ice free by the end of summer, 2020 CE.
Depends on how much oil gets spilled in the intervening years, doesn't it? I had the impression a thin layer of oil changes albedo, wave height, everything that matters. No?
oh no! the poor polar bears! but....they will be ok,obviously.
William, maybe a little bit off-topic, but what is your estimate of Paul Beckwith's claim (member of AMEG, think you wrote about them before), that we might experience an increase in temperature of 6° within a decade?
He claims this in this video (https://www.youtube.com/watch?feature=player_embedded&v=zw1GEp8UBj4#!), sry I don't have one of his papers available.
Any comments on that?
[My opinion is that you should ignore everything that AMEG say, unless you can find a more reliable source saying it :-). 6 oC globally is obvious nonsense. 6 oC in the Arctic... sounds pretty dubious too. I'd bet against it, unless you phrased it as something like "over the bits of sea formerly ice covered but now open" -W]
Well, we did have +18C +/-4C in the mid-Piacenzian at ~350 ppm CO2 in a more-or-less equilibrium state and the models can't replicate it, so it's not entirely off-base to wonder if we might be seeing the start of a transition to something like that. OTOH anything like a specific prediction lacks support.
But back to certifiable current events:
I point to this.
And I point to this.
What sayeth the Stoat?
[What a lot of pictures. Remember, I was a climate modeller so have little to say to all this surface detail. I note that this year is currently looking good, but then so did 2012 -W]
ok, I searched for an Interview with Beckwith, found it, and he really seems to mean six degrees global mean. Why the hell is he claiming hogwash like this? (Overview of interview is here, if anyone wants to look http://www.ecoshock.info/2012/12/climate-arctic-thermostat-blows-up.html)
[But... why are you taking these people seriously? -W]
I am not taking them seriously, seriously. I am just wondering why someone obviously not stupid ( he seems to be rather smart ) keeps on making such very strange, improbable claims.
There is smart-smart and there is stupid-smart. Have to keep your smarts separated or they will begin to smart.