It's time for the annual blog about the annual Nucleic Acids Research (NAR) database issue. This is the 24th database issue for NAR and the seventh blog for @finchtalk. Like most years I have no idea what I'm going to write about until I start reading the new issue. Something always inspires me.
This year's inspiration came from missing data.
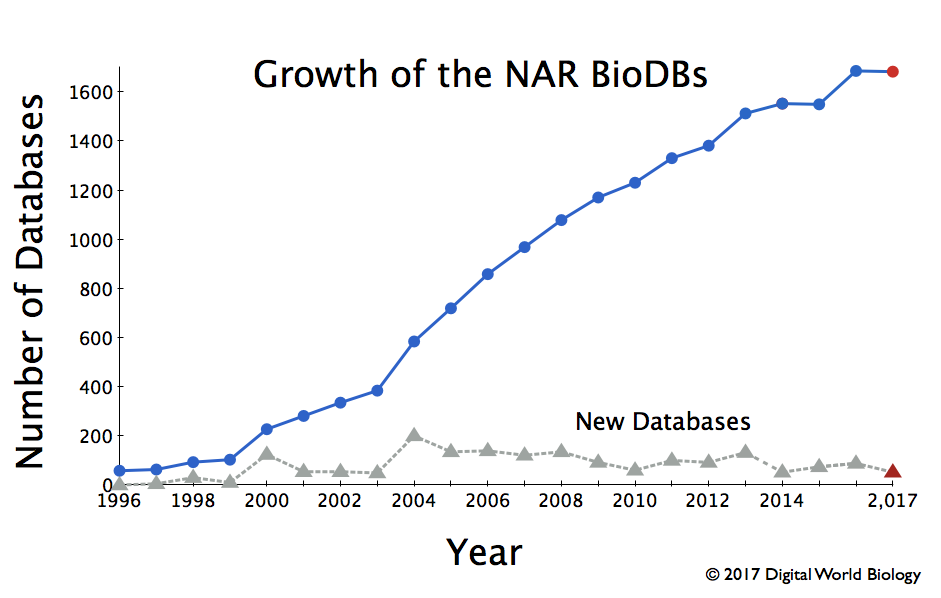 In 2017, NAR lists 1662 databases or 23 fewer than last year.
In 2017, NAR lists 1662 databases or 23 fewer than last year.
As summarized in the database issue's introduction, Galperin, Fernández-Suarez, and Rigden tell us this year's issue has 152 papers. 54 of those describe new databases, 98 provide updates, and 16 are updates of databases that have been published elsewhere. 18 duplicate entries and 30 obsolete database have been removed. But we are not told how many databases are in the catalog. That is an exercise for the reader.
Given that last year the authors stated that there were 1685 databases one would assume that this year's total would be 1685+54+16-18-30=1707, or 1691 if the 16 updated databases were in the catalog and just described somewhere else. But, since we are not told that, we need to figure it out on our own.
Fortunately, the entire list of databases is available, so all you have to do is visit the page and count the entries. Ok, that would be tedious and take forever because you'd have to check your work and likely get lost several times doing so. Instead, one can capture the text and write a Perl script to count the entries. When I did this, I got 1662 for an answer. This is neither 1707 nor 1691. As the catalog is maintained through the year, more databases have likely been removed than were reported in the article.
As I counted the entries, I also looked at the titles and descriptions and thought about what could we learn from this information. After all, these 1662 databases are used to develop scientific knowledge. Can we use this data to learn about the kinds of things scientists are interested in?
 Now my simple Perl script grew from a command line that counted empty lines to a script that had to grab the second line of each entry - triggered by an empty line using a state machine, with an initialization to get the first entry - parse that second line and count the words. For students interested in bioinformatics, this is a common exercise with data.
Now my simple Perl script grew from a command line that counted empty lines to a script that had to grab the second line of each entry - triggered by an empty line using a state machine, with an initialization to get the first entry - parse that second line and count the words. For students interested in bioinformatics, this is a common exercise with data.
Once that was done, a review of the words indicated some clean up was in order. Common words, that added little value, were removed. Also, plurals were converted to singular forms to avoid duplication of terms. The last step was to use wordle™ to create a tag cloud of terms found in the database descriptions.
So, what did I learn?
First, database is the most common term. Nearly 25% of the descriptions use that term. The next most frequent term is protein, which is followed by gene, genome, human, sequence, and data. The term structure, something we're interested in at Digital World Biology, is the eighth most frequent term. It is followed by genomic, interaction, and expression.
While DNA sequencing captures attention in the news, understanding how genotypes impact phenotypes requires that we deeply understand the relationship between sequence, structure, and function. Thus, it is not surprising that the most common terms describing biological databases would include words that describe this relationship. 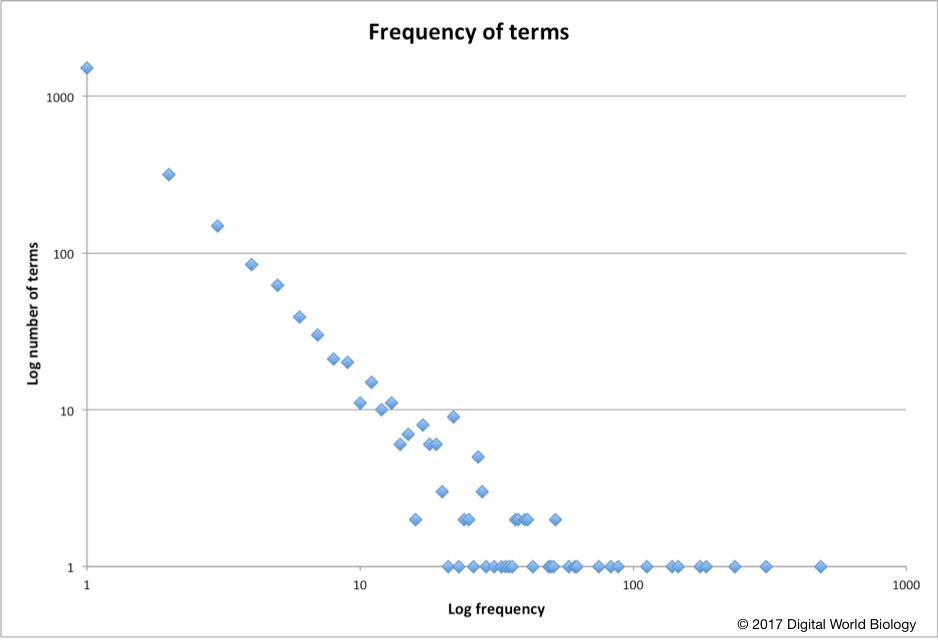
The other interesting finding is the sheer number of unique words. The tag cloud above summarizes 150 of 2370 total words. To be listed in the tag cloud a word had to used at least nine times. Words used only once occurred over 1500 times. These are interesting and instructive too. A few of the words indicate that there are databases that include information on waterfleas, mites, exosomes, leptospira, paramecium, amoebazoa, honey, plexipus, bananas, and many others. The words used once list also includes misspellings, word fragments, and words that add context to descriptions, many of these are chemical and biochemical terms.
The real importance of the number and variety of words used to describe the databases however, is that biological databases store and organize data and information about biology. And, the complexity of biology cannot be stored in a single source.