
In my last post, I wrote about insulin and interesting features of the insulin structure. Some of the things I learned were really surprising. For example, I was surprised to learn how similar pig and human insulin are. I hadn't considered this before, but this made me wonder about the human insulin we used to give to one of our cats. How do cat and human insulin compare?
It turns out, that all vertebrates produce insulin, even frogs and zebra fish. Human preproinsulin is only 110 amino acids long and even human and fish insulin are pretty similar. Of course, this observation only leads to more questions. Like why? Why would fish insulin and human insulin be similar at all?
One clue comes from insulin's function. Many cells require insulin for growth. Another clue comes from the insulin structure. A key feature of the insulin protein is a pair of disulfide bonds that hold the two chains (A and B) together.
 Disulfide bonds between chains A and B in human insulin, PDB ID 1TRZ
Disulfide bonds between chains A and B in human insulin, PDB ID 1TRZ
When insulin is made, it's made as one long protein (preproinsulin). Afterwards, a small part gets cut off at the amino end when it gets transported through the membrane. Later, another chunk gets cut out of the middle (C peptide) leaving the two disulfide bonds between cysteine residues holding everything (Chains A and B) together.
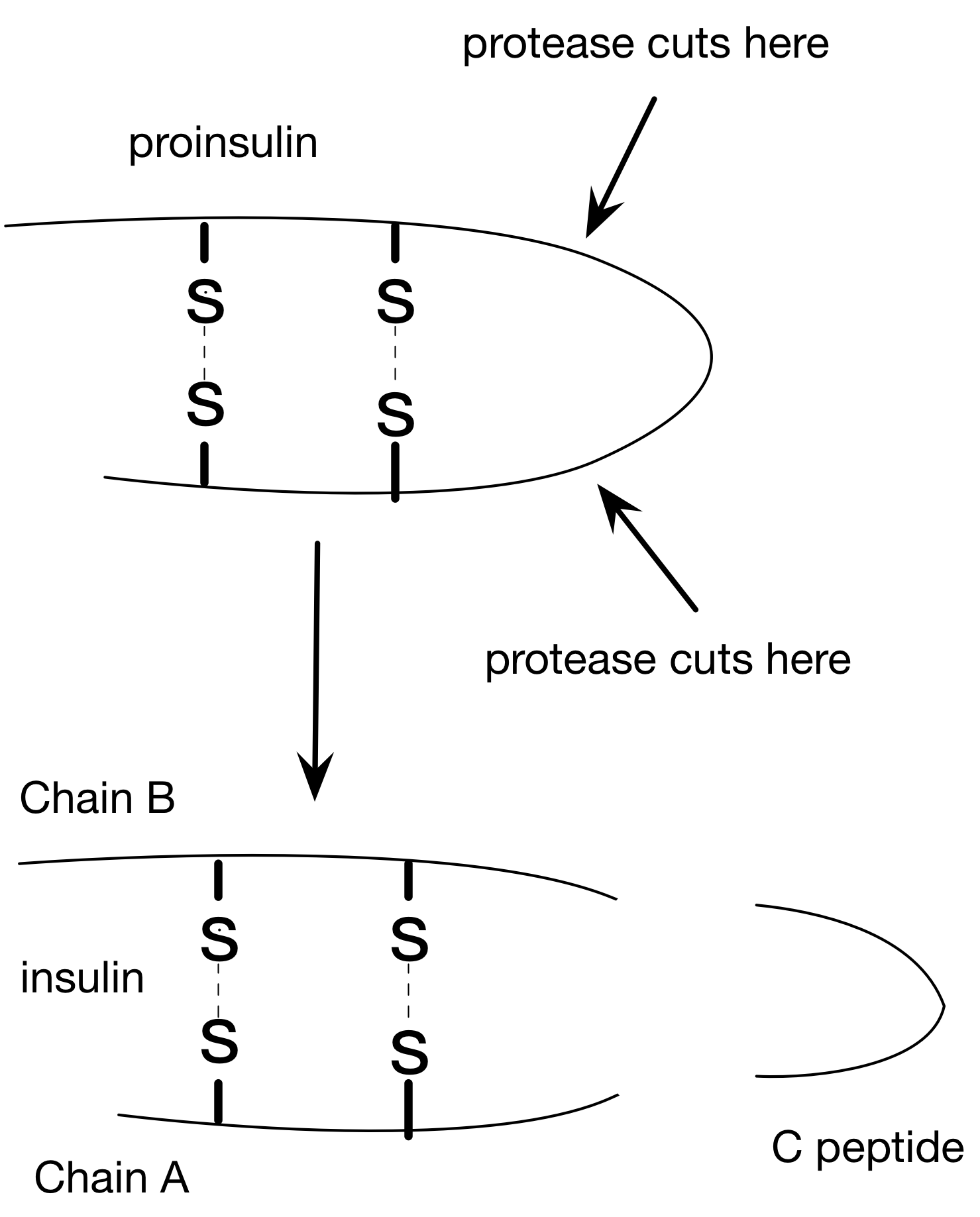
Those four cysteines look like they must play a pretty important role since they're charged with the task of holding it all together. This made me wonder: Do all the creatures that make insulin have cysteine bonds in the same positions?
To test this idea, I needed a way to identify those four cysteines within the insulin protein.
I opened 1TRZ (the human insulin monomer) in Molecule World* and applied molecule coloring to identify chains A and B. Then, I hid all the protein chains, and one by one, touched the C's in the two sequences to highlight the cysteines.
Once I found all the cysteines, I touched some of the C's again to deselect the ones that formed disulfide bonds within a chain and used the "Hide unselected" button to hide them. Now, we only see the cysteines that hold the A (pink) and B (blue) chains together.

The protein sequences are a little dim, but I can see the one letter abbreviations for the amino acids around each cysteine. These sequences help me spot where these cysteines were located in each chain of the protein.
Assembling the data set
The next step was to put together a set of sequences. I picked protein sequences since I wanted to include some distant relatives (worm & fly). To find the protein sequence for the human insulin gene (INS), I searched the gene database at the NCBI. The INS gene record contained a link to Homologene, a database that I used to get similar insulin protein sequences from other organisms. Curiously, I found that that mice and rats have two insulin genes! That was a surprise! Do rodents really consume that much sugar? I decided to include both rat insulin 1 and rat insulin 2 genes, since I didn't know which one was most important. As it turned out they're pretty similar to each other.
I also used the NCBI Gene database to get sequences from C. elegans (a nematode, a type of small worm) and Drosophila ananassae (a type of fly, related to Drosophila melanogaster).
Time to BLAST!
After compiling my list of accession numbers, it was time to run blast. I chose blastp from the BLAST home page at the NCBI and checked the "Align two or more sequences" box to compare my human insulin sequence to a set of other sequences.
Then, I pasted the accession numbers for my data set in the subject field and clicked BLAST.
BLAST results
All the sequences matched and had significant E values, even those from the fly and worm proteins.

But what about the cysteines?
Curiously, NCBI protein blast has this new feature and a new algorithm (to me anyway) for multiple alignments, called Cobalt.
To create a multiple alignment, you just click the "Multiple Alignment" link on the blastp results page.

Voila! You get a multiple alignment from Cobalt!
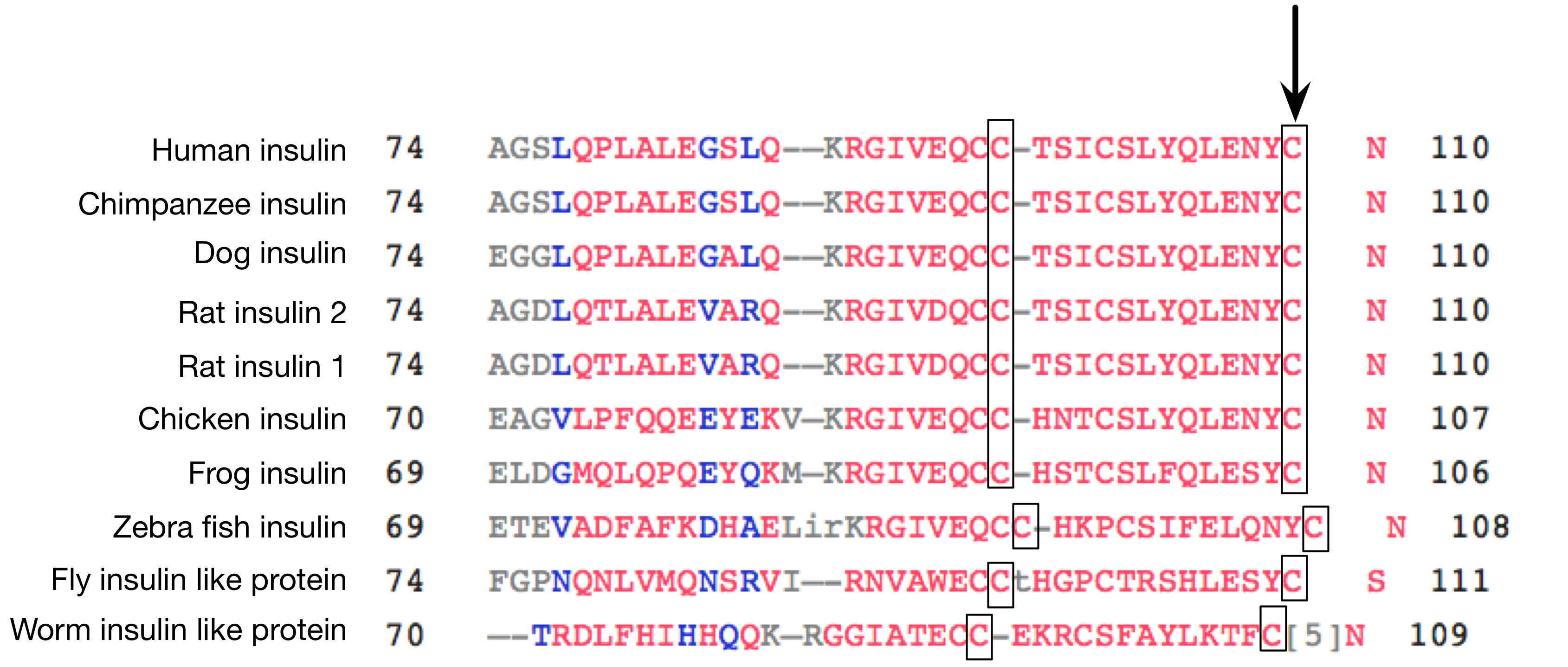
I think this alignment could be improved by a bit of editing, but the general idea is pretty clear. Even flies and worms keep those cysteines in the right place.
NCBI's Cobalt results will even let you make a phylogenetic tree. Those, this was a little bit flaky. Sometimes, I would click the link and see an error message saying the page wasn't there.
Nevertheless, sometimes, I could click the Phylogenetic Tree link, and sometimes, get a tree. And, it even makes sense.

Images & Bioinformatics software: All the images in this article were made from the new version of the Molecule World™ iPad app (Digital World Biology). Many of things we do with Molecule World can also be done with Cn3D, it's just a bit more complicated.
The 1TRZ structure was obtained from the NCBI's Molecular Modeling Database. The protein sequences, from the NCBI, and the blastp algorithm and Cobalt were used at the NCBI.