Boosted from comments. Robert Chung writes:
David Kane wrote:
Anyway, it seems clear to me now that you are bluffing
Me, bluffing about knowing how calculate a CMR? Ouch, that hurts.
David, what a fascinating example of hubris. You do not know how to do something, so you conclude that no one else can either. However, that something "seems clear to you" has, once again, led you down the wrong path -- though for you this seems about par for the course.
As you ought to have known long ago, we are clearly not "in the same boat." The reason you ought to have known this long ago is that you have had in your possession the proof of what I have been saying -- but with the blinders you're wearing you couldn't see it. 20 months ago, I showed a graph with the cluster CMRs; more remarkably, 14 months ago and then again one month ago, both times in response to your own requests, I have pointed you to my code in which can be found the "magic formula" for calculating the pre- and post-invasion CMRs. Perhaps you missed it since the calculations were cyptically and misleadingly labeled "pre-invasion CMR" and "post-invasion CMR"? I leave getting the overall CMR from the cluster CMRs to you as an exercise.
{kind=link}
I, and others, have warned you that you have been confounding the estimates of CMR and the estimates of the CIs around those estimates. You keep saying that my estimates of the CMRs and excess mortality depend on bootstrapping. They do not. The proof is in the code you ignore. You keep saying that Roberts' estimates of excess mortality depend on normality. They do not. Despite your exegesis of the rest of the article, the proof is at the bottom of the left hand column on page 3, where the CMR calculation is given. Look at it, and please (please!) recognize that it does not depend on normality.
So this is what it comes down to: the estimates of excess mortality don't depend on normality, but your argument does, and there is no evidence that Roberts and Garfield made that assumption. You have done this even though there is no evidence for it and, in fact, there is evidence against it. Your argument is a phantom argument. There is nothing there. This is what Tim Lambert meant when he said that all you've shown is that assuming normality for the CI including Falluja is wrong.
David, there are legitimate criticisms of the Roberts and Burnhams articles. Yours isn't one of them. Your paper is trash, and you're hurting yourself. Do the right thing. Write Malkin and Fumento and tell them you didn't know what you were talking about. Tell them you apologize for the exploded heads. You can even tell them you're working on yet another crazy argument. You don't have to tell them that you accused a demography professor of not knowing how to calculate a CMR.
I've been curious about a common element that adds a little zest to these controversies even if the controversies are phony or ginned up. Can anyone explain to me why scientists are seemingly reluctant to provide the underlying code in their studies? Is it an research/IP thing? Doesn't it make peer review more difficult?
Most importantly, is this the 500,000th comment?
Tim,
Are you sure that commentator "Robert" is Robert Chung *and* that he wants his identity revealed here? I have no reason to doubt your claim, but, unless I have missed something, "Robert" has never revealed his last name before and has provided his code/graphics at anonymous sites. Clarification from you, "Robert" or Robert Chung is welcome.
"Robert"
By the way, my claim is not that you are bluffing about how to calculate a CMR in general. Anyone can look up the formula for that. My claim is that you can't show us the code which produces the answer that is reported in L1.
In fact, let me call you out again. You failed to quote my entire sentence -- very rude behavior in the Deltoid community. I wrote:
What line in your code produces these numbers using the normal approximation, as the L1 authors used? Nothing that I can see . . .
That's a bit like Custer asking his aide, "are you SURE those are Sioux warriors slaughtering my troops?"
"Can anyone explain to me why scientists are seemingly reluctant to provide the underlying code in their studies?
Is it an research/IP thing?"
Of course. That and trying to avoid the myriad questions on how to actually build the code which will inevitably follow unless you have taken the time to make your code distributable. And if you have taken the time to make your code distributable it will certainly already be publicly available.
"Doesn't it make peer review more difficult?"
Absolutely not. If you're at the point where you feel the need to check someone's work in detail you need to write your own implementation of the algorithms they claimed to use. Starting with their code is just a lazy, half-assed way to verify work you don't trust. If you can't write you're own implementation of the algorithms you aren't qualified to check the code either.
>> Can anyone explain to me why scientists are seemingly reluctant to provide the underlying code in their studies? Is it an research/IP thing?
> Of course. That and trying to avoid the myriad questions on how to actually build the code which will inevitably follow unless you have taken the time to make your code distributable.
I disagree on both counts. Claiming that your software does something without providing the code is akin to claiming that you proved something without providing the proof, saying that you want to keep it secret or saying that it is not in a "distributable" state. It should be unacceptable, but for some reason it is.
>> Doesn't it make peer review more difficult?
> Absolutely not. If you're at the point where you feel the need to check someone's work in detail you need to write your own implementation of the algorithms they claimed to use. Starting with their code is just a lazy, half-assed way to verify work you don't trust. If you can't write you're own implementation of the algorithms you aren't qualified to check the code either.
Again, I disagree. Without the code there are often many implementation details that are left ambiguous and could significantly impact the results.
Robert (Chung?:-) did provide code - the Iraq mortality study authors should have done the same, but they would be the exception if they did.
"Without the code there are often many implementation details that are left ambiguous and could significantly impact the results."
There are valid reasons for not giving out one's computer code (not least of all the fact that such code often takes considerable time and effort and competitive advantage in one's future research may depend on it) and the argument for doing so in all cases is simply not convincing -- at least not to me.
While that is often true that there can be ambiguities without the actual code, this depends a great deal on what the code does and how complex it is. Straightforward statistics can be -- and is -- done with a large variety of different computer codes with the very same results for all practical purposes.
If the documentation for the algorithm and its implementation are good enough, someone should be able to reproduce the results no matter how complex the program is. That's really not as hard to do as some people make it sound.
Also, if one is checking the implementation of the algorithm itself, it is always best NOT to use the same code. That way, one can increase the likelihood that one will catch computer coding errors.In other words, one can make sure that the algorithm was properly implemented.
Of course if you use exactly the same code you should get the same result! If you don't, there is something very seriously amiss.
So what if someone can reproduce the results with the same code? Big deal. Other than catch gross errors, what does that really accomplish? Not much, I'd have to say.
Floundering desperately, David Kane wrote:
[You've](http://scienceblogs.com/deltoid/2006/11/lancet_podcasts.php#comment-260…) [missed](http://scienceblogs.com/deltoid/2007/03/london_times_hatchet_job_on_la…) [something](http://scienceblogs.com/deltoid/2007/03/london_times_hatchet_job_on_la…). Quelle surprise, eh? I guess we can add those posts to the list of things you've missed like, for instance, how to calculate a CMR. I'm pretty comfortable with who I am and I don't think I hide it. Many Deltoid regulars have known it for a while. Besides, exactly who I am is pretty irrelevant--it's funny but irrelevant. What's funny and relevant is that you have had the actual evidence before you for so long, both from me and from the Roberts article. No matter who I am, the fact remains that despite all your blustering I, in fact, do know how to calculate a CMR and you, in fact, do not. I think most people would agree that actually understanding mortality rates well enough to calculate them is, um, you know, probably kinda important if you're thinking of critiquing a mortality study.
What, you want to call me out again? Dude, you still got marks on you. Don't you want to let the swelling go down a little or dab on some Bactine or something? David, altering the claim after the fact and then acting as if it was there all the time is way past rude--it's deceptive. Worse, it's stupidly pointless deception: anyone can go back and see what you've done. The original claim was about the CMR. You added the rest afterward. Desperation breeds stupidly pointless behavior. Don't be desperate. It's unbecoming.
This is so much fun that I want to invite others to play. As Tim has kindly noted before, I collected and cleaned up the (released) data from L1 in a handy R package which you can download from CRAN. Once you do, you can do stuff like this:
> library("lancet.iraqmortality")
> data(lancet1)
> mean(lancet1$pre.mort.rate)
[1] 5.3
> mean(lancet1$post.mort.rate)
[1] 14
>
In words, if you just take the simple cluster mean of pre and post CMR, you do not get the same estimate as reported in L1. Why not? Good question! I do not know how to replicate the results reported in L1 and do not think that Robert Chung, despite being a professor of demography, can do it either. That is our dispute. (The estimate reported in L1 is 5.0 for pre-war and 12.3 for post-war.)
If Robert can reproduce those numbers, he should prove it instead of just flaunting his credentials.
And, he might be able to! If he can, we would all learn something. Science progresses by such small steps.
But I bet he can't . . . .
Note that I am not implying bad faith on the part of the L1 authors on this point. The calculation they performed was (I believe) a reasonable one which made use of more data than they have actually released. Robert can't replicate it, not because he is stupid, but because no one can.
No one has replicated the results from L1 using the same methods as the authors use.
just a reminder to those of you working in non-epidemiology scientific fields that building epidemiological models requires an extensive process of model-building that is not automated. The code is not a "program" as such, but a series of instructions and judgements by the epidemiologist, often including digressions to produce graphs and the like. Disputes from the code will tend not to happen; but unresolvable disputes about the model-building decisions will almost always happen. Often the code may not be particularly accessible - in SPSS for example, residual graphs are almost always constructed from menu options, so it is impossible for the "code" to be sufficient for the model-building process.
This is in essence what David Kane is doing without seeing the code of L1 - he takes issue with the exclusion of Fallujah, which is a model-building decision taken after judging the outcome of the starting model (e.g. examining leverages, etc). There are no confounders in the model that I am aware of, so the rest of the model-building process is trivial and not open to dispute.
Epidemiologists pretty much have to assume that the code is irrelevant, and tackle these "operator" decisions (e.g. by emailing the author to ask "did you consider this variable and if so how").
In fact if an epidemiologist sent me the code for a model, and I could run that code and get the final model without any intervention or checking by me, I would consider the model to be dodgy straight away. That means they have used an automated model selection procedure, which is straightaway suspicious for anything but the most regular of data.
Not that it matters in this case, since David Kane hasn't given any evidence that he could understand any code he was sent by the L1 authors.
JB,
So you are presenting two cases:
1. The code is simple. If the code is simple, why not just publish it and resolve any potential ambiguities? It seems that this is the case of the Lancet Iraq studies.
2. The code is complex. If the code is complex and contributes significantly to the results in the paper then it should be considered an essential part of the paper, and must be published even if that would reduce the "competitive advantage" of the author. Science is supposed to be about sharing your information - you have to have a very good reason to withhold information. If you want to keep your competitive advantage, just don't publish.
And yet, you wouldn't put any effort into reversing the damage done by your right-wing bloggy/media buddies by saying something as simple as "I was wrong! Please, tell all your readers and listeners that I was wrong!"
Damage done. That's the point. "Oh, I have a result that matches my political bias, I'm going to tout it as being the truth!" without regard as to whether or not you know what the hell you're talking about.
We know you don't care, David...
David Kane sniveled:
Oho! A bet! Excellent! What will you bet? How about what I suggested earlier? You write to Malkin and Fumento and tell them you don't really know what you're talking about?
Robert,
I am sorry but arguing with you is getting boring. The only claim on this topic that I have ever made is that no one, including you, has been able to replicate the CMR estimates published in L1. I'll make it again. L1 estimates 5.0 for pre-war CMR and 12.3 for post-war CMR. Use the data that Tim provides and show us the R code which produces those numbers. You can't do it. (Admittedly, the comment which seems to have upset you is unclear.)
I never claimed that you, or anyone else, can't calculate a CMR in general. You, or anyone else, can since the formula is trivial. I did question your bona fides to lecture me on the topic. Alas, despite being a professor, you have failed to act like one on this thread.
ffs,
David:
>pre.cmr<-12000*sum(lancet1$pre.deaths)/sum(lancet1$pre.person.months)
>pre.cmr
[1] 4.993758
satisfied?
furthermore
>post.cmr<-12000*sum(lancet1$post.deaths)/sum(lancet1$post.person.months)
>post.cmr
[1] 12.30867
satisfied?
I did it with your data frame (I renamed it lancet1 for some stupid reason). When you say you can't replicate the L1 CMR, what exactly do you mean?
Since neither of those people will care nor publish a correction, how about additionally requiring him to post that letter here?
On behalf of the many people who don't use R, I am pleased to confirm that I have been able to replicate SG's figures using an Excel spreadsheet.
Will that do, David, or should I be demanding that Microsoft release their source code?
Sortition:
perhaps you neglected to read my very next line (after the simple/complex part)
"If the documentation for the algorithm and its implementation are good enough, someone should be able to reproduce the results no matter how complex the program is. That's really not as hard to do as some people make it sound.'
I've done software engineering (over a decade) and programming (going on 30 years) long enough to understand that with proper documentation, it is quite possible to reproduce the same output (though the actual code may be quite different).
If that were not the case, most statistics packages would give different answers for the very same input.
The key element with science is that you provide enough information that someone who is "skilled in the art" can repeat the results. That does not mean you have to give them every last detail. In fact, in most cases, the assumption is made that the person reading your paper is going to have enough background in the area to understand the basic ideas and steps without listing every one of them like you would have to do with a complete novice.
SG wrote:
Damn you, SG. I was hoping to hustle David into a bet.
For everyone else, SG's calculation is exactly what any epidemiologist, biostatistician, or demographer would have done; it's what Roberts and Garfield must have done. David Kane was calculating an unweighted mean of the cluster CMRs thinking that would get him an overall mean. That only works when the cluster sizes are all the same. In this case, the cluster sizes aren't very different -- but they're just different enough that anyone doing careful analysis needs to take it into account. David doesn't do careful analysis.
Kevin has checked this with Excel so others can, too. You may want to use [this file](http://anonymous.coward.free.fr/misc/iraq.csv), which is already in .csv format and can be read directly into Excel.
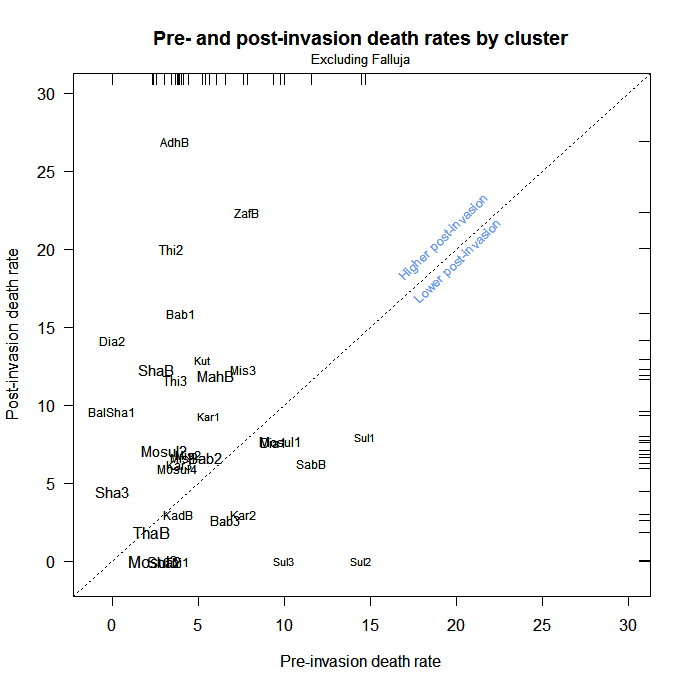
1. Is the properly calculated pre-invasion CMR = 5? Yup.
2. Is the post-invasion CMR = 12.3? Yup.
3. Is the pre-invasion CMR excluding Falluja = 5.1? Yup.
4. Is the post-invasion CMR excluding Falluja = 7.9? Yup.
You can calculate the excess mortality including Falluja: 17.8 months, 24.4 million people:
(12.3 - 5)/1000 * (17.8/12) * 24400000 = 264000
To calculate the excess mortality excluding Falluja, do the same thing as above but remember that in excluding Falluja, you're only estimating for 32/33rds of the country:
(7.9 - 5.1)/1000 * (17.8/12) * 24400000 * (32/33) = 98000
The relative risk including Falluja: (12.3/5) = 2.5
The relative risk exluding Falluja: (7.9/5.1) = 1.5
No assumptions about bootstrapping. No assumptions about normality, or any other sampling distribution. All of the estimates reported in the Roberts article, replicated.
David, once again, you have shown that you are eager, determined, self-confident, clueless, misguided, and incompetent. Your entire argument is built on: "I can't figure it out, so no one can; since no one can figure it out, why bother asking anyone else?" David, you're spanked. You're drubbed, whupped, and schooled. You deserve all of it. You need to read [this](http://www.google.com/url?sa=t&ct=res&cd=2&url=http%3A%2F%2Fwww.apa.org…).
One more thing: "Michael Fumento! Michelle Malkin! Tim Curtin! Shannon Love! Can you hear me? Your boy took a hell of a beating! Your boy just took one hell of a beating!"
"Alas, despite being a professor, you have failed to act like one on this thread."
What does it mean to "act like a professor"?
Do all professors act (behave) the same when subjected to the same external forces?
or, put another way, are professors more like apples? Or like electrons?
Is there an "Uncertainty Principle" for professors?
These are very important questions.
So, its that simple and absurd? Kane simply didn't know he had to adjust for cluster size?
I've been loosely following this argument, without bothering to dive ina nd look at the data myself. In this thread, it's been clear that Robert Chung already knew what the issue was, and had the same results as Lancet, or he would not have been baiting Kane so strongly. I was looking forward to seeing what the issue was, and expecting something interesting and perhaps even a bit subtle, something from which I might learn a bit about demography.
But - a failure to consider weighting, with different cluster sizes?
I'm just a poor biologist, mathematically acceptable but no more, trained through linear algebra, fought my way successfully through p-chem and stat methods, spent my time in SAS on a Vax-VMS, just enough training to know that I ALWAYS want to confirm any complex analysis with a competent statistician - but even I am startled, befuddled, bemused - astounded, actually - that anyone who considers himself competent to make this kind of attempted critique could make, and defend without thought that he might be wrong, that kind of basic error.
David -- just stay down!
I am impressed someone can do the calculations easily in Excel, but also, what's wrong with R? I got R to help a scientist friend overseas (I couldn't help debug stuff with it till I knew how to use it). It's a great system, geared excellently to "checking out" and "checking in" large data sets. And it's free!
Sortition wrote:
"I disagree on both counts. Claiming that your software does something without providing the code is akin to claiming that you proved something without providing the proof, saying that you want to keep it secret or saying that it is not in a "distributable" state. It should be unacceptable, but for some reason it is."
and
"Again, I disagree. Without the code there are often many implementation details that are left ambiguous and could significantly impact the results.
Robert (Chung?:-) did provide code - the Iraq mortality study authors should have done the same, but they would be the exception if they did."
I guess we have a fundamentally different understanding of what a journal article should be. The point of an article ought to be to report particular results, not to claim that some code does 'X'. That's what software companies do, not scientists.
In the course of reporting your results you need to give enough information so someone could reproduce your results. If there are ambiguities that could significantly effect the results you haven't really given enough information to reproduce the results, have you? I would further claim that in general you should give the minimum amount of information needed to reproduce your results or your paper turns into a description of your coding practices and other methodology rather than a discussion of your results.
Lee said: "So, its that simple and absurd?" Kane simply didn't know he had to adjust for cluster size?"
I think this is precisely what the person who invented the term "cluster-fuck" had in mind.
JB,
> I've done software engineering (over a decade) and programming (going on 30 years) long enough to understand that with proper documentation, it is quite possible to reproduce the same output (though the actual code may be quite different).
This is certainly true since it is a tautology. The problem is that we may have a hard time agreeing what constitutes "proper documentation." If the code is provided, then there is no room (or at least much less room) for disagreement. I have seen many published papers which left enough details undocumented to allow significant manipulation of the results.
But even if we accept your claim that publishing the code is not always necessary, I cannot see what damage would be done by always doing so. Without a good reason not to publish the code, it seems best to always publish the code, even if sometimes it may not be necessary.
The point of an article ought to be to report particular results, not to claim that some code does 'X'. That's what software companies do, not scientists."
never claimed that a scientific paper should just "claim that some code does X"
Perhaps you are not familiar with the term "Documentation" as it applies to computer software, but if it is done such documentation is done properly, it tells you all you need to know to reproduce the same output for a given set of inputs.
Say I write a paper that claims i have a method for finding the hypotenuse of a right triangle given its two legs (contrived, I'll admit, but it serves to illustrate my point)
To demonstrate the result, I can either
1) provide the computer source code that does it
2) give the result for one right triangle and tell how one can reproduce the same result for that triangle (and other right triangles) -- ie, by "documenting" the algorithm (ie, Pythagorean theorem) and its implementation.
Actually, I don't even need to document the implementation in the above example. Anyone who knows anything about computer programming at all should be able to reproduce the result from the Pythagorean theorem alone.
For scientific purposes, 1 and 2 are equivalent, (though #2 admittedly takes more work on the part of the person trying to repeat the experiment)
The only difference between that simple example and more complex problems is the detail that is required in the documentation. but that does not mean it is not possible. In fact, it is done at software houses every day throughout the world. If documentation is good (complete, accurate), it is all that is needed.
> To demonstrate the result, I can either
> 1) provide the computer source code that does it 2) give the result for one right triangle and tell how one can reproduce the same result for that triangle (and other right triangles) -- ie, by "documenting" the algorithm (ie, Pythagorean theorem) and its implementation.
Again: I have seen many papers that claim to do 2), but leave enough details out so that what they actually do becomes significantly ambiguous. You will probably claim that those papers were not well written, which may be true, but they were published nonetheless.
Again: I do not see any reason not to require both 1) and 2) - do you?
I will certainly agree that saying something can be done in practice does not mean it will be done. in fact, that is a major problem with far too many software projects -- that the documentation does not adequately describe the program.
But there are certainly no guarantees of anything in life. :)
I already provided the reason why i think people should be able to keep their source code private. It really is a matter of competitive advantage.
If a scientist -- Stephen Wolfram, for example -- puts years into a software project like mathematica and then uses it to calculate results for a scientific paper, does that mean he has to provide the source code for his Mathematica program? (note I am talking about the underlying source code for mathematica)
I think not, but i think we probably have an unresolvable disagreement on this -- and it all boils down to a matter of opinion anyway.
> It really is a matter of competitive advantage.
So the idea is that you give proper documentation so that your competitors could reproduce your work, but you don't give the code so that it is not too easy for them to do it?
To me, this seems like a nasty hybrid between science and business. It also appears to encourage writing deliberately vague documentation to make the lives of the competitors even harder. If to you this approach makes sense, then I guess we will indeed have to agree to disagree.
Marion Delgado,
One attraction of using Excel rather than R is that the data is already available as a spreadsheet here. Les Roberts made it available to David Kane - to whom all credit for taking the trouble of chasing after it and passing it on to Tim Lambert. It's a pity he didn't have Robert Chung by his side to show him how to use it! Incidentally, for those who don't like paying Microsoft for spreadsheet software, there is always Open Office .
I'm sure R is well worth learning. But the spreadsheet is surely the simplest tool for showing that David Kane's critique really doesn't amount to much. There is no point demanding to see the code used by researchers to obtain estimates if all the code has to do is simple arithmetic. Obviously the calculation of the bootstrapped CIs around the estimates is another matter; it would be interesting to know exactly how that was done. But it's hard to see that anything important turns on it, except for the people dsquared aptly calls percentile fetishists, who will no doubt feel the earth move if they can find some semi-plausible algorithm which squeezes 2.5 percent of the excess-death CI below zero, even if the upper 2.5 percent limit goes to the stratosphere.
So the idea is that you give proper documentation so that your competitors could reproduce your work, but you don't give the code so that it is not too easy for them to do it?'
That is precisely it.
Telling someone (even in detail) how to do something is a far cry from handing them the source code that allows them to immediately start where you are and improve on it.
Like business, science is competitive, in case you had not noticed.
Actually, there is another major advantage (to the actual science) that I alluded to above: independent calculations (coding) are better than dependent ones.
If someone writes their own code to verify your results, it is much more likely that coding errors will be caught. There is a very famous example of a very involved computer calculation in physics that got an answer that was NOT consistent with QED Theory. A lot of people spent a lot of time scratching their heads (years) wondering why the theory di not agree with the experiments, until it was realized that the groups that had done the calculation and come up with the same answer (supposedly independently) had actually shared their work at a critical point.
They all made the same error, which would not have been the case had they each done the clauclation from scratch.
So yes, there is a major advantage to be had from doing that.
The other advantage -- and this is actually an advantage to the person trying to reproduce the results is that there is a chance they will notice something that the first experimenter did not, or at least come to a fuller understanding of the problem.
I must say that I really do think it is a matter of laziness more than anything else when it comes to demands for providing all source code.
> Like business, science is competitive, in case you had not noticed.
Only too well (if by science you mean academic activity as it is happening in reality). But it shouldn't be that way and doesn't have to be that way, at least not to the extent it is.
Somehow, when teaching science we always emphasize the collaborative and open nature of the activity. The ideal, it seems, is very different from reality.
Sortition -
Since your questions about releasing code were interesting and valid, please read JB's replies, because I think he answered them completely. Releasing code could make it less likely to catch the inevitable errors.
And, (at the risk of piling on), thanks to all for making your excellent education of Mr. Kane so very clear.
[David Kane was calculating an unweighted mean of the cluster CMRs thinking that would get him an overall mean]
I just threw up a little bit in my mouth.
On the more interesting subject, I am on Team Sortition. In general, more code ought to be made available. On the other hand I do agree that it shouldn't be part of the peer review process for the reasons JB mentions - if you're checking someone else's work you shouldn't be using their code, for by and large the same reason that you will *never* learn anything from a textbook that has all the answers to the problem sets in the back.
> Since your questions about releasing code were interesting and valid, please read JB's replies, because I think he answered them completely.
I beg to differ. I feel that my points regarding papers which produce results that are ambiguous due to missing details in the specifications of algorithms have not been properly addressed. Saying "then the authors should have put more details in" is just wishful thinking, not a solution.
BTW, I always make a point of reading closely what the people who respond to me write, even though sometimes I get the feeling that my efforts are not reciprocated.
> Releasing code could make it less likely to catch the inevitable errors.
On the contrary - it is usually claimed that one of the advantages of open source software is that having many people view the code makes it more likely that bugs would be caught.
If I develop my code according to your documentation and I discover that my results differ from yours, it would be very difficult to discover if I have a bug, you have a bug, both of us have bugs, or (the most likely situation) I simply made a few design decisions regarding certain details that are different from your decisions.
Whereas if you run the same code, you'll get the exact same numbers and never know there was a problem.
"On the contrary - it is usually claimed that one of the advantages of open source software is that having many people view the code makes it more likely that bugs would be caught.'
My experience is that visual inspection of source code is actually not a very good way to find bugs. This is because source code is usually not very well documented and scientists in particular (not computer scientists but other ones) are notorious for writing spaghetti code that uses gotos and other such niceties that make it virtually impossible to follow.
Much easier to follow higher level documentation of what the code does (or at lest of what it is supposed to do). BTW, there is also an advantage to forcing scientists to provide documentation for their code in that it may increase the chances that they find errors in their own implementation.
What it comes down to is this:
If two groups do a calculation independently (using the same methodology, algorithms, etc, but different coding) and get the same answer, the likelihood increases that they have at least done the coding right. The algorithm could still be faulty of course, but presumably if they have provided that in the documentation, someone can also check that.
On the other hand, if they get different answers, then that is a flag that there is a problem, of course. More investigation is then required to determine what the problem is. Clarification on the part of the original investigator may be required at that point. This is really not any different from the way science has always worked (ie, before computers came onto the scene).
i have seen this argument about showing source code many times before and one thing has always puzzled me. Perhaps it is because I was trained in science some time ago, but when i was at university learning to write scientific papers, i learned to describe my methods and materials so that someone with a reasonable understanding of the subject might repeat my experiment.
For some reason, that standard seems to have changed. Now it seems to have become "Do everything for the next guy -- so he/she does not have to do anything except start the program and write down the numbers that come out.".
Robert Chung seems to have done that for David Kane above. I find it absurd that someone would have to do that for a researcher at a University like Harvard.
pough:
> Whereas if you run the same code, you'll get the exact same numbers and never know there was a problem.
Why would you just run the same code on the same dataset - that has been already done and reported on. The idea in providing code is to enable other people to examine the working of the algorithm and to apply it to other datasets.
JB:
> i learned to describe my methods and materials so that someone with a reasonable understanding of the subject might repeat my experiment.
I don't know your work - it may be up to the standards of excellence you put up (although, apriori, you do seem overly self-confident here). There are, however, many papers which are not up to those standards. In those cases I need to see the code to understand exactly what was done.
You have given two reasons for not releasing code:
1. To maintain competitive advantage.
2. To force others to repeat the coding work as a way to verify correctness of the results.
I find both of these arguments to be anti-scientific. The first is a way to handle adversaries or do business, not science. If we accept the reasoning in the second argument, we might as well never publish any results at all since some people may accept those results at face value rather than examine them for errors. We can similarly argue that if we don't publish results, we force others to duplicate it and in that way verify it.
most people don t release their code, because they want to clean it up, before somebody sees it.
most short code, written by an individual , will contain ZERO documentation and several unelegant constructs, that need real work to be replaced.
most people are busy these days, so they simply don t find time to invest into working code.
-----------------
most people will provide the code, if personally asked by a person with reasonable interest.
it would be nice, if more code was awailable, but it is not realistic to hope for it.
> most people don t release their code, because they want to clean it up, before somebody sees it.
> most people are busy these days, so they simply don t find time to invest into working code.
> it would be nice, if more code was awailable, but it is not realistic to hope for it.
It is simply a matter of making it a requirement for publication. People find the time to handle all the other requirements of publication - I see no reason why this would be any different.
Sortition and dsquared make the case for openness, but I think it is trumped by the need for independent verification. Don't we need experiments to be run by different people, in different times and places, to be confident that the conclusions are robust? JB's example of the error being propagated in QED is cautionary.
Also, what happens as code is modified by others? Whose is it? Who is responsible for errors and updates? It could easily become distracting.
Well, first you'd have to show ...
1. Utility. Hand waving, so far (and I manage an open source project)
2. Career protection, and yes, this is very important in a world where tenure, or pre-tenure hiring at top univiversities, is competitive-based. You can say "science shouldn't be like this" or - as is hinted above "scientists shouldn't care (i.e. scientists shouldn't try to get the best job at the best $$$ they can)". Change the structure of science hire/fire tenure/non-tenure policies, then maybe individual scientists will work as you think they should work.
> Well, first you'd have to show ... 1. Utility.
The prime utility, as I have stated several times, is removing ambiguity regarding what exactly is going on. As I have stated several times, I have seen many papers where the description of the procedure is far too short on details to remove ambiguities on several significant issues. Additional scrutiny of the code for bugs is a secondary benefit.
> Hand waving, so far
Is this a way to have a discussion?
> #2. Career protection
I don't really see what is the problem here. Requiring to publish code is not qualitatively different than requiring disclosure of many other details of the work being published - requirements which are standard practice.
As I have stated several times, you might as well suggest that divulging proofs of theorems risks your career because it lets the competition know too much - if they want to know the proofs, they should get off their lazy behinds and figure out the proofs by themselves.
1) I thank SG for replicating the CMR estimates for L1 and showing us all how he did it. This is how science is supposed to work! Someone (like SG) who knows something explains it to someone (like me) who doesn't.
2) I thank Robert Chung for replicating the excess death estimates for L1. I think that Robert's attempts to bait me into a bet were not how a professor ought to act, but opinions may differ on that score. It was because I thought that these estimates could be replicated that I declined to be trapped. But, to learn something new, I am always ready to be ridiculed, so ridicule away.
3) But we still have a problem! No one has replicated the confidence intervals for these estimates. Can anyone do so? I do not think that it is possible with the data that the L1 authors have released, but I have been wrong before.
And just to be clear that I am not the only puzzled member reader, I'll note that sensible Kevin Donoghue wrote:
Now, it is my understanding that the confidence intervals for the CMRs were not done with a bootstrap but with a normal approximation, in essence, whatver the standard STATA command spits out. I do not know if the excess death estimates involved the bootstrap. I think that they did not, that the bootstrap was only used for the relative risk confidence intervals.
Is there someone in the Deltoid community who can answer Kevin's question? He (and I!) would appreciate it.
David, it's time for you to do what you love demanding of others, and show us your code. Exactly what code did you use to calculate CMR's, which failed to replicate the results from the paper. Did you, perchance, get values of 5.3 and 13.7? If not, what did you get? You claimed above to know how to calculate the CMR (it's "trivial") so why couldn't you replicate it?
Show us the code.
And btw, David, your point 1) has not got anything to do with how "science is supposed to work". What has gone on here is how first year students are supposed to learn. A simple formula in a textbook, applied in a simple calculation package (or in this case, on a piece of paper), and the correct answer obtained.
You didn't even look at a textbook and now you claim that we are "all" learning something? And having been shown that everything you claim can't be replicated can be, you still insist on us proving to you that the CIs are accurate?
Kevin Donoghue wrote:
Thanks for that reminder, Kevin. Here's something cool: cells T37 and U37 on the 'All data' sheet contain the pre- and post-invasion CMRs, and cells T36 and U36 on the 'without Falluja' sheet contain the CMRs without Falluja. As formulas, not as values, so not only can you see the values but you can also see how those values were calculated.
Hmmm. David has charged that Roberts et al. knew including Falluja would expand the CI to include zero, so they suppressed that information in their article and just focused on the "without Falluja" results.
However, in this case, David converted that spreadsheet into an R package, recommended that everyone use his package, but suppressed the one line that showed the overall CMRs. Then he insisted that "no one knows how they did it, and no one has ever been able to replicate it."
So, which is it? Is David really a dishonorable fraud who willfully made knowingly deceptive statements after manipulating the data, or is he just an incompetent braggart with Dunning-Kruger syndrome? I vote for the latter, but then I'm a generous guy.
Excellent comments! I do, indeed, try to practice what I preach. Unfortunately, I am travelling right now, so the full answer will need to wait till Tuesday, but in the meantime I can offer the following.
1) You can download the latest version of my R package from here. I believe that this package includes the spreadsheet exactly as I downloaded it from Deltoid. Shame on me for not looking closely for formulas in the cells as Robert points out. The package includes both the pdf of (that version of) my paper along with the .Rnw document which produced it. This document (in Sweave format) lists every formula used. The package itself includes every function. You can replicate every detail to your hearts content.
2) But that version of the package is not the same as the one which supports either the paper as Tim so kindly posted it or the paper as I presented it at ASA or the current version of the paper. Once I get back to the office, I will immediately post a version of the .Rnw for the paper as Tim published. (I think that will be easy to do; I just hope that I have an appropriate notation in Subversion, my source control system.) If I don't have that version easily accessible, I definately have the ASA version, which is almost the same in all respects.
3) Given a couple of days, I will get the paper and the package into a format that can be updated on CRAN. (Without the latest version of the package, it may not be easy to replicate what is going on in the .Rnw file.) This is not as easy as it sounds since the newest version of the package includes all sorts of data from Jon Pedersen, some of which I can distribute and some of which I can't. So I need to be careful about that. Perhaps Tim will even be kind enough to host a new version of the pdf (which is much cleaned up and improved after our previous endless thread on the topic).
Robert,
You wrote:
I have just checked the R package linked above and, indeed, I did distribute the entire Excel spreadsheet including the cells you reference. I "suppressed" nothing.
And, for the record, I believe that no one has replicated the confidence intervals for L1 and it is, obviously, those confidence intervals that are the focus on my paper.
Can you replicate those confidence intervals?
Shame on me for not looking closely for formulas in the cells as Robert points out.
hm. a pretty weak excuse. your paper uses the term CMR exactly 118 times. but you didn t look at how its calculated in the data you examine?
(again, it was LABELED CMR!)
Given a couple of days, I will get the paper and the package into a format that can be updated on CRAN.
i have some doubts that people are interested in more of your stuff. are you spreading out the news among right wing bloggers, that your results should be taken with a grain of salt?
after it turned out you had some deficiencies in knowledge on the subject?
doesn t this event slightly change the approach you should take to the critisism your paper received here?
by the same people who educated you on this subject now?
sod asks:
No. Interestingly enough, I think that Roberts and Garfield provide a fair summary of my paper.
Fair enough, although I prefer to label myself a statistician rather than a political scientist. In other words, the estimate of the CMR is irrelevant to the point of the paper. I have no dispute with the CMR estimates themselves. My claim is that the confidence intervals for those estimates imply something about the confidence intervals for the excess death and relative risk estimates (i.e., that the intervals include no increase in mortality) and that the L1 authors purposely hid that fact.
Now it might be fair to use the fact that I did not notice that line in the spreadsheet as evidence of my carelessness but that is a separate issue.
Meanwhile, back at the ranch...
Civilian Death Toll in Iraq Climbs
Reuters
>Saturday 01 September 2007
>Baghdad - Civilian deaths from violence in Iraq rose in August, with 1,773 people killed, government data showed on Saturday, just days before the U.S. Congress gets a slew of reports on President George W. Bush's war strategy.
>The civilian death toll was up 7 percent from 1,653 people killed in July, according to figures from various ministries."
[end reuters quotes]
/////
It seems to me that further "discussion" with Kane is a waste of time.
Whether Lancet numbers are overestimates or not, one hell of a lot of people have died in Iraq -- with an error bar of "1/10 of a helluva lot". And its not just the deaths that matter, of course. The country is experiencing a crisis of unimaginable proportions. Pretty much every piece of information that has come out of Iraq lately supports that contention, including what was reported in the above article and indications that cholera is on the rise due to a health system on the "verge of collapse" and the fact that millions of refugees have been created (both inside and outside the country).
Who really gives a flying f...k about what David Kane and his god-damned, unsupported speculations about fraud and the rest?
It seems to me that he got FAR more information and time from actual experts here than one person could ever hope for. And he then has the audacity to belittle those he is getting the information from ("You are bluffing, Robert", etc)? Only from a Harvard Don could we expect such hubris.
David Kane, using the normal approximation to the poisson distribution for 46 deaths I can get a confidence interval of 3.6 to 6.4. Using the exact limits I can get 3.7 to 6.7 (this for the pre-invasion death rates, obviously). You can find the formulae for these online (there's even a webpage which will do the calculation for you). Either calculation is equally acceptable (look it up in Bland).
I can do this using ONLY the information given in the paper, not using your data, not using any fancy cluster-based crap, JUST the information in the paper.
Do you consider 3.6 to 6.4 to be a sufficiently close replication? Or do you now choose to hang your entire argument on the fact that a replication using only the information in the paper is out by 0.1/3.6, i.e. 2%?
David Kane, refusing to stay down asked:
Yes. Think I'm bluffing?
Robert, if you had played your cards right, you would have been able to retire by now.
I think you played your ace one hand too late.
Then again, maybe not.
"Hmmm, he's got 4 aces showing, I wonder if he's bluffing."
No. Interestingly enough, I think that Roberts and Garfield provide a fair summary of my paper.
yes they do. but i think it s scientific standard to give an ACCURATE (has nothing to do with FAIR) description of a paper.
perhaps you missed their EVALUATION of your paper:
First, in spite of Mr. Fumento's article, a -30% death rate is not possible unless you believe that all the dead people from the past 15 years can come back to life. Secondly, imagine that if you took 32 water samples in your child's school and found that arsenic samples were 60% higher than the national standards, and you were 98% sure that you were above the standard. Then you took one more sample that was ten times higher than the standard. The logic endorsed by Michael Fumento is that we do nothing about the water supply because this outlier broadened our statistical confidence interval and we are not sure that we are above the national standard.
i don t want to break it to you, but that translates into a pretty shitty /totally useless" paper (FAIR enough)
Now it might be fair to use the fact that I did not notice that line in the spreadsheet as evidence of my carelessness but that is a separate issue.
that was the MAIN issue of my post above!
that you did not notice this, shows the same carelessness that you displayed in investigating CMR, in reading the excel sheet, in reading the comments by robert and others and in distributing your baseless paper to rightwing blogs.
again and slow:
you mewssed up big time. the people who corrected you, think that MORE is wrong with your paper. start taking their concerns seriously!
I like it when they pick a hill to die on, then proceed to do it.
Over on Rabett Run there's a furious debate on archiving knowledge vs. the Interwebs. This particular series of tubes should be preserved as long as possible.
In a certain sense I am going to say the opposite of what's normally said "I suspect that's not the last we've heard of ..." no. I think that at least in a sense where he isn't highly suspect, we are seeing the last of Mr. Kane.
In case the issue at hand - the aggression by the US and UK against the formerly sovereign nation of Iraq and the subsequent typically disastrous colonial occupation thereof, didn't make it clear: Propensity to mistakes + humility and a willingness to learn from others = the human condition, really. Propensity to serious grave error + a core belief that ideology should be able to push numbers anyway you want them to go + a truly profound belief that you're never wrong = megadisaster for most people, even if you're rewarded for it in the short term.
Kevin: thanks for the response above. It makes perfect sense.
Marion, Propensity to serious grave error + a core belief that ideology should be able to push numbers anyway you want them to go + a truly profound belief that you're never wrong = megadisaster for most people, even if you're rewarded for it in the short term"
That's spot on.
At the root of the entire Iraq debacle are people who put themselves (career, ideology, you name it) ahead of everything and everyone else.
And despite being proven wrong again and again (and again), they keep pushing their BS on the rest of us.
The best way to deal with such people is to push them aside and then simply ignore them because, above all else, attention and recognition are what they crave.
For someone who admits to not really knowing what they're talking about, you've allowed your "debunking" "work" to be touted all over the right-wing blogosphere as though it were written by god on stone tablets.
Shame on you.
SG writes:
Fair enough. Here is the code for the paper that Tim posted. Note that, as the discussion which followed showed, there are some mistakes there. Also, it is not complete in that it uses some functions in the new version of the R package that I have yet to release. Given a week or so, I will have a new version of the package and the paper that, with luck, Tim will think worth posting and discussing. I would recommend waiting for that version.
SG writes:
Sure, does that same trick work for the post-invasion death rates? I don't think so. You are only off a little from what the paper reports using this approximation because the between-cluster variance is so low for the pre-war CMRs. That isn't true for the post-war CMRs, so the trick doesn't work.
Robert Chung claims to know how to replicate the confidence intervals for the CMR estimates. I have asked him to do so. Kevin and SG are also interested in the same thing. Why does Robert refuse to enlighten the rest of us? I don't know. Whatever his complaints about my behavior, surely Kevin and SG are innocent bystanders and deserve to know the answer. Good professors answer questions.
Apologies but the link above to the draft posted by Tim should go here.
And, lest cynics think that no progress is being made, I will note that Robert has already cleared up what was a mystery to me (and to many other Deltoid readers). He wrote:
This is the first time that I have seen anyone replicate the 98,000 number. My own attempts got close (100,000) but never exact because I used 5.0 instead of 5.1 in the formula above. In other words, I used the pre-war mortality rate estimated from all clusters (since there was nothing remotely outlying about the pre-war numbers from Falluja) whereas Robert (and, I assume, the L1 authors) used only the non-Falluja data. There is nothing wrong, I think, with either approach.
This is helpful because now the next draft of my paper will get this correct. Thanks! I also think that this clarifies a lot of the misunderstanding in the previous thread about whether or not the bootstrap-derived confidence intervals for relative risk have anything to do with the excess death estimates. My reading of the paper has always maintained that they don't, that all you need is CMRs in order to calculate excess deaths. Many (including dsquared, I think) argued the opposite. Roberts replication means, I believe, that I am correct on this score. The L1 authors calculation of excess deaths has nothing to do with the bootstrap. Would others agree?
Kane said:
"Robert Chung claims to know how to replicate the confidence intervals for the CMR estimates. I have asked him to do so. Kevin and SG are also interested in the same thing. Why does Robert refuse to enlighten the rest of us?"
Actually, Kane, the rest of us are enlightened. Robert knows what he is doing, and you haven't got the first clue.
He is baiting you, Kane. You've shown you havent got clue one to be approachign this field, you keep implying everyine else is wrong (about the next thing, now that you;ve been schooled on the last) and now we're all just laughing (sadly,but laughing) at the spectacle. Robert is helping in that.
Dude, Kane, YOU DIDNT THINK TO ADJUST FOR FRICKING DIFFERENT CLUSTER SIZES!!!! I todesn tget much more basic than that. And when you got a different answser, you didnt say, maybe I'm missing something - you made a public argument that the authors did somethign that no one could follow. Yo hae been implying dishoensty left and right. and you dont know what the hell you are doing. There comes a point when the only appropriate ongoing response is to laugh at you, and this is where we're all at now.
David Kane said: "This is helpful because now the next next next next next next next next next next next next next next next next next next next next next next next next next next next next next next next next draft of my paper will get this correct."
My personal experience shapes my ideas about code. Some time ago a bunch published a calculation on something we were doing at Rabett labs, but the answer was not very realistic. So I went and tried to replicate the result, and got a reasonable (and different answer:). At that point I went looking for the code and found it in the thesis of the student who did the calculation . . it was an awful mess with multiple compensating errors and one big one, but the only reason I was able to spot these was that I had already worked through the problem. My conclusion is that the only time the actual code becomes important is when someone who knows what he is doing (Robert) has problems replicating the answer.
Eli:
> the only time the actual code becomes important is when someone who knows what he is doing (Robert) has problems replicating the answer.
Nailing down specifics in the case of problems replicating results is a clear case where having published code does you good.
But I would argue that there are other reasons to publish code.
One such reason follows from Eli's story: if the authors of the erroneous published calculation had to publish their code, they probably would have cleaned the code as part of the writeup of the paper, and so might have caught their own errors. This would have saved everybody a whole lot of trouble.
David Kane whined:
Hmmm. Perhaps, but the best professors do whatever they can to dispel ignorance and promote knowledge. Yes, in many cases that does mean answering questions; however, in your particular case, the situation is far more complex. You actually destroy knowledge, and your paper creates ignorance. In this situation, the way to be true to my professional responsibilities is to not be your enabler and to assure you that I ain't your monkey. I'm sure the other Deltoid readers will understand.
Two more things:
1. You know when you said you think of yourself more as a statistician than a political scientist? I'm guessing a lot of statisticians are asking "why us?" and a lot of political scientists are high-fivin'.
2. Remember when you wrote "[j]ust wait till the demographers chime in..."? How's that working out for you?
David Kane, I can't adjust for cluster sampling with my available software, so I can't get the exact answer from the paper for the post-invasion deaths - as you say for the pre-invasion deaths it doesn't matter much.
Is your argument that this is a problem? That you want to be able to replicate the cluster analysis as well? Because this is ludicrous. You can't even calculate a CMR, and you want to try and calculate the CMR after adjusting for the clustering and probability sampling? You will make stupid mistakes and then you will tell Malkin and Fumento that you couldn't reproduce the results; after which someone here will have to stumble about fixing it up, and you will never correct your claims.
So, since every other calculation in L1 has been shown to be correct, why don't you just get over it, accept that the published design effects are correct, and stop annoying everyone with what you think.
Can everyone stop mutilating the David Kane's intellectual corpse? There must be some international convention you are violating.
Sortition -
You ask us to respect D Kane's intellectual corpse, but he is not only alive and well but both fabulously wealthy (CEO of Kane Capital Management) and highly regarded (Harvard IQSS faculty).
In his spare time he helps people believe that violence in Iraq could not possibly be as bad as the Lancet study demonstrated.
The stench of corpses is Iraqi. The moral stench is shared by deniers such as Kane and cheerleaders like Malkin and Fumento.
SG writes:
I thank SG for taking the time to respond. Comments:
1) Recall that the main question that my paper tries to answer is: What would the excess death estimate (and associated confidence interval) be if we include the Falluja data? Now, you wouldn't think that this would be so hard to figure out, that the authors ought to be willing to just answer that question, I question that I put to them privately years ago, but here we are. AFAIK, no one has publicly answered that question. You may think that it is a boring or stupid question. Perhaps it is. But it is the question that I am going to answer.
2) Is just the available software that is the issue? As is clear (!) to all, I am not a demographer and have never done this sort of analysis before. It is too bad that someone like Robert Chung, who clearly knows what he is doing, spends his energy baiting me rather than answering Kevin's question. I had thought that one needed more detail than the cluster level data provides. Would you mind providing a brief description of the steps involved?
3) Given my goal in 1), the first step is, obviously, to replicate what the L1 authors did. Can I, using their data and their methods, get the 98,000 estimate along with the 8,000 to 194,000 confidence interval? So far, I can't. Can anyone? Robert has provided (thanks!) the formula for the estimate, but it does not appear that just plugging in the confidence interval for the CMR without Falluja produces the excess death confidence interval. Note how this confidence interval is not symetric about 98,000. Why would that be?
4) So, my argument is not that it is a problem in and of itself that I can't replicate various results in the paper. Lots of published results can't be replicated! My problem is that I can't (easily) answer the question that I want to answer --- Excess death estimate and confidence interval including Falluja using the exact same data and methods as L1 --- without understanding precisely the methods used in L1. We have made much progress in that regard. Recall the thousands of words written about whether or not the CMR confidence interval was derived from a bootstrap. But, alas, there is still further to go.
Thanks to everyone who has helped in this process and to Tim for providing such a useful forum.
David, I have revised my earlier comment at 69, because I have discovered that R has a package called "survey" which makes it possible to adjust for probability weights. So I could go through the necessary steps to reproduce the design effects, etc. but to do so I would need the data at the level of household. Except perhaps for a few higher order corrections, it seems that R can calculate everything you need for this problem if you know how to do it.
Unfortunately you need data to the level of the household, which we don't have. And the reason we don't have it, David, is almost certainly not related to fraud, attempts to hide the truth, or any other such paranoid conspiracies. It is because the authors are not going to release data in breach of their Ethics agreement, and certainly not to someone who cannot calculate a CMR. i.e. you.
As for your other comments:
1) you have the design effects, you have the variances. Why not just do the calculation?
2) no. The operator needs to understand the maths, not be a hack, and have access to the data at the level of the household. The authors meet these three criteria, you fail all three.
3) The confidence interval could be asymmetric because they have calculated an exact confidence interval using the poisson distribution. I seem to recall Robert calculating this figure exactly, but this whole imbroglio has become too tiring to follow all the details. Your complaint seems to be that you don't understand something, therefore it must be wrong.
4) David, if your problem is that you cannot reproduce the results of paper A without understanding precisely the methods used in paper A, I would recommend that the solution would be to go away and study the methods. You seem to think that if you don't understand it, the authors are pulling the wool over your eyes.
I will leave with the words to a Suicidal Tendencies song: "just because you don't understand it don't mean it don't make no sense." I suggest you think about that, go away and get yourself an education in biostatistics, and while you're at it email all those right wing hacks you love and tell them how wrong you have been.
Further, David, Robert has given you the formulae for calculating excess deaths at comment 18. If you use the (design effect - inflated) confidence intervals for the post-invasion death rate, i.e. the value of 5.6 (minimum) and 10.2 (maximum), you can calculate the excess mortality rate confidence intervals. You'll find they're 17500 to 165000, i.e. the confidence interval is narrower than that published. So the bootstrapping has actually widened the confidence interval of the excess deaths estimate, by 10,000 deaths at the lower end and 30,000 at the upper.
I know your complaints about this paper have changed too many times to count, but in some prior incarnation, weren't you saying that this bootstrapping was done to mislead the reader into rejecting the null hypothesis with greater confidence?
Mark Shapiro said: "You ask us to respect D Kane's intellectual corpse, but he is not only alive and well but both fabulously wealthy (CEO of Kane Capital Management) and highly regarded (Harvard IQSS faculty).
In his spare time he helps people believe that violence in Iraq could not possibly be as bad as the Lancet study demonstrated."
Kane had better just pray that none of the other Harvard IQSS faculty read Deltoid in their spare time.
...and that someone does not drop one of them a "Howdy, want a good laugh?" note -- and link.
>Whatever his complaints about my behavior, surely Kevin and SG are innocent bystanders and deserve to know the answer. Good professors answer questions.
SG has already more-or-less disassociated himself from this eloquent plea on his behalf. Borrowing from another SG, I must also say include me out. My experience of good teachers, including a few professors, has been that they answer questions in the Kerryman's manner, by posing another question of their own. An appropriate question in this case might be, are you sure you are ready to play at this level? Good professors look askance at students who want to tackle advanced material when they haven't mastered the basics.
Another good professorial response is: your line of thinking is flawed (or in Bohr's immortal words: "that's not even wrong" - good professors are not always kind). You are asking why the Lancet did not publish the bootstrapped CI for excess deaths including Falluja. What use would it be? Robert Chung has already shown us what it looks like. It's the sort of thing I would expect to see used in a textbook as an illustration of how bootstrapping doesn't solve all problems. Sometimes you just don't have enough data.
Certainly I would like to know more about the algorithm used to produce the published ex-Falluja CI. It seems wide which (as SG notes) is unhelpful to your case. But if what you are planning to do is to plug the Falluja-inclusive data into the same program - disregarding those textbook warnings - and then use it to support some daffy argument for the likes of Malkin and Fumento to deploy, that's not scientific enquiry. To put it politely, it's a fishing expedition. But it may keep you from doing something even less constructive, so I hope you find it absorbing.
> [Kane is] fabulously wealthy (CEO of Kane Capital Management)
I doubt that he is wealthy. The whole purpose of his Lancet paper is obviously to gain respect among right-wing circles. If he was wealthy, he would not need to resort to dubious PR excercises to gain respect in those circles. His wealth alone would have been more than enough.
Usually attributed, I think, to Wolfgang Pauli, but your point stands.
Conspicuous by its absence has been a response by David Kane to the many comments urging him to send a retraction, erratum, anything to the various right-wing bloggers who so gleefully pounced on his paper, without understanding it, after he sent it to Michelle Malkin. How about it, David?
Comments:
1) SG writes:
Exactly. Or, at least, this has been my understanding. Without data at the household level (which has not been released to anyone for L1) it is impossible to replicate the CMR estimates and confidence intervals for L1. If Robert disagrees with SG on this point, I hope he will educate us all. Previously, he has claimed to be able to replicate the confidence intervals.
2) Kevin writes:
Me too! Again, Robert claims to be able to replicate this CI, but I don't think that he can. Certainly, if the CI for excess deaths depends on the CI for CMR and if SG is correct that no one can replicate the CMR CI without access to the household level data, then Robert is just making stuff up. But both SG and Robert know more about survey research then I do, so it is tough for me to judge who is right. I think it is SG.
3) SG asks:
I do not think that my complaints have changed so much as expanded. Only two drafts of the paper have been published on the web, both kindly linked to by Tim. The second cut out many of the complaints from the first, mainly because they had to do with the data from L2 and I wanted to focus on L1. All my complaints about the L2 data still stand. In particular, the response rate for L2 is, in the words of a past president of the American Statistical Association, "not credible." More on that some other time.
Also, I continue to believe that the bootstrap was used in L1 in order to get the result the authors wanted. How many other published papers can you site that use a bootstrap with 33 (!) observations? I don't know of a single such paper. Counter-examples welcome!
So many misconceptions, so little time.
The usually sensible SG writes:
It may be fun to speculate why the authors don't distribute the household-level data from L1, but keep in mind the following.
1) Les Roberts claims that this data is no longer "available."
2) It is highly unlikely that the terms for the "Ethics agreement," of whatever the binding protocal might be, are that different between L1 and L2. (Some) Household data was released for L2, more or less to almost everyone who asked. (Last I heard a dozen people/teams had asked and only two groups (Spagat et al and one other) had been turned down.
3) Having had extensive e-mail contact with various Lancet authors, I am pretty sure that some of them have no problem with me. (Les Roberts does.) For example, after I pointed out numerous mistakes/inconsistencies with the data from L2 (which I do have access to) Shannon Doocy thanked me in an e-mail to all the teams who have received the data. (As I side note, the behavior of some of the Lancet authors, especially Doocy, has been helpful and highly professional throughout. Many thanks to them!)
4) Les Roberst, during the question and answer session at ASA, said that, if it were up to him, none of the data would be released to anyone. Fortunately, more professional folks like Burnham and Doocy seem to have prevailed on that score, at least with regard to L2.
jre asks:
There is nothing to retract! Again, now is not the time to re-open the endless thread, but the big message of the paper still stands, although many details will be fixed in the next version. I hope to cajole Tim into posting the next version so that you can see that.
Also, isn't this a bit of a Catch-22 for me? dsquared and others yelled at me for "allowing" Malkin to post the last draft. If I tell her about the next draft (which will indeed correct some mistakes from the previous version), am I a bad person for doing so (as people argued last time) or a good person (as jre seems to argue here)? Just asking!
Seriously though, what does the Deltoid community want me to do when the next draft comes out? E-mail Malkin/Fumento/others or not? You tell me. Of course, it won't matter much since Malkin, at least, reads Deltoid, but I just want to be clear on what I should do.
As to the thuggish comments from JB and Sortition, I like to think that such commentary has no place at Deltoid. Perhaps I am naive.
David Kane: "thuggish comments from JB and Sortition."
That you claim something does not make it so. That should be clear to anyone who reads what you have written in this thread.
So many misconceptions, so little time.
do you even still notice your arrogance?
99.9% of the "misconceptions" are YOURS!
but now that we know that you have access to money, there is a simple solution:
i think i can remember the Lancet author told us, how cheap the study actually was (50000 $ or pounds is the number stuck in my mind..)
so why not SIMPLY replicate it?
but please do all of us a favor: simply ask someone to do it. do NOT get involved in anyway whatsoever.
instead you might want to take a look at some undergraduate textbooks.
then if a completely destroyed part of fallujah is polled, you can interpret the result in whatever way you want: claim that all iraqis are dead, or that we can t tell whether there ever were any iraqis to begin with.
There is nothing to retract!
hm. malkin decided to make a huge issue out of the "impossible to replicate" thing.
why not start by telling her, that some things were VERY EASY to replicate, but that you simply couldn t figure it out?!?
http://tinyurl.com/2ybnnz
Again, now is not the time to re-open the endless thread, but the big message of the paper still stands,
that main thesis NEVER "stood".
again:
the people who are educating you on rather basic stuff, believe that the "main point" of your "thesis" is utter rubish.
obviously, that doesn t make you think..
and you could at least try to reply to Roberts example:
so what would you do about that arsenic school water?
http://www.spectator.org/dsp_article.asp?art_id=11935
Also, isn't this a bit of a Catch-22 for me? dsquared and others yelled at me for "allowing" Malkin to post the last draft. If I tell her about the next draft (which will indeed correct some mistakes from the previous version), am I a bad person for doing so (as people argued last time) or a good person (as jre seems to argue here)? Just asking!
why not simply tell the truth?
tell them that you have shown incompetence in basic stuff, and that there s serious doubt about the conclusions of you paper.
tell them that you need to study some more, and that they better post disclaimers into the original article and on their website.
personally, i d start with feeling slightly ashamed, about my own incompetence, if i were you. but i guess that s a matter of personal preferences..
David Kane at comment 80:
David, why do you think some of the household data is available from L2? Because some would have been identifiable data, and was therefore withheld. L1 is a smaller study, therefore more of the household data is identifiable. And how do you know that L1 and L2 have the same rules? L1 is the first study, so its rules may have been made more restrictive and the authors may have argued in L2 for looser rules precisely because of your accusations of fraud. You continue to wilfully misunderstand the obligations of epidemiology researchers, who deal with people, and have additional responsibilities.
At comment 79:
This is such an incredibly arrogant, thuggish and disingenuous comment I don't know where to start.
Arrogance: Even with the data at household level it is impossible for you to replicate the result, because you don't know how to do any of the necessary calculations for this type of work (you can't even calculate a CMR, don't know how to calculate excess deaths, and can't calculate a relative risk CI from a generalised linear model - how can you possibly do the probability weighted analysis?)
Thuggishness: You continue to insinuate the need to replicate the results, while everyone around you points out that no-one's honesty is in question.
Disingenuousness: the salient details of this paper have been confirmed, yet you insist on pretending that further confirmation is needed.
You obviously haven't pondered the wisdom of the Suicidal Tendencies quote I gave you. Go back and think about it some more...
Here's what I don't understand:
* Has any epidemiologist raised any major concern about L1 or L2?
* Has the study generated any major dispute in the field, such that standard methodology was put into question?
* Has it engendered any major critique of how epidemiological research is routinely done that would point out shortcomings that the field as a whole must address?
If the answer to all these questions is "no" -- and as far as I can tell, it seems to be -- then what the hell is David Kane talking about when he keeps implying that his speculations about the study are all in an effort to make science progress?
Maybe *he* is learning a lot about epidemiology, and certainly *I* have benefitted enormously from reading all the discussion about the studies, but both he and I are laymen on issue. What have real practicing epidemiologists learned from any of this?
If they haven't learned anything, than all that is happening is that David Kane is getting some free lectures.
Another question: why keep focusing on L1? The study is slightly dated now, and most importantly, was replicated in L2, wasn't it?
As for the following:
> "*All my complaints about the L2 data still stand. In particular, the response rate for L2 is, in the words of a past president of the American Statistical Association, "not credible."*"
Didn't the UNDP survey have a **98.5%** response rate?
> "*...but the big message of the paper still stands...*"
Which is *what* exactly? That you can't replicate the CI and therefore the authors must be either wrong or outright falsifying research? I hope you realize how much of a non-sequitur that is...
The bottomline is that if practicing epidemiologists don't see the results as problematic, then they probably aren't. If you can't understand the methodology and cannot get the same results yourself, then tough luck. If you are not convinced, then you should push for another study to be made by an independent group, and not do a disservice to everyone and keep obfuscating an important issue...
Honesty would be nice.
Of course. "I am full of shit and I'm very sorry for it" would be a good lead sentence.
Agree to quit lying, which is in essence what you are doing, for starters.
dsquared wrote: "[...]I do agree that it shouldn't be part of the peer review process for the reasons JB mentions - if you're checking someone else's work you shouldn't be using their code, for by and large the same reason that you will never learn anything from a textbook that has all the answers to the problem sets in the back."
Checking the implementation and checking the methods could be cleanly separated. Upon submission, just give the first to the proper reviewers and let some computer science grad students look at the code. Spaghetti Fortran, yum!
Then it would be sent back with reluctant approval and a stern note to do it in OCaml next time.
Sortition wrote:"[...] you might as well suggest that divulging proofs of theorems risks your career because it lets the competition know too much"
Careful now, don't give them ideas!
For diogo, Here is information on the ILCS/UNDP response rates. Again, if you think Fritz Scheuren doesn't know about conflict surveys, you should go fight with him, not me.
SG writes:
I have provided the only, as far as I know, detailed decription (pdf) of the data that was actually released in L2. As you can see, there is nothing there that, if released on the same basis for L1, would identify any individual. I am communicated with the authors extensively on these topics and I am pretty sure that, if the rules were different, the authors would have told me. Again, Les Roberts reports that the L1 data is no longer available. If that is true, no one will ever replicate the confidence intervals for the CMR estimates from L1. (That statement assumes that SG knows what he is talking about and Robert Chung does not.)
SG writes:
Again, you and I have a meta-dispute about whether or not replication is necessary or even desirable. Fine. But it is not just me that you have a dispute with. Start here for an introduction to this debate.
As penance for my sins, I have written up a brief discussion on non-response which explains why the formula used in L1 is not as obviously correct as Robert Chung, SG and others like to pretend. Any comments on that should be directed to this thread on Deltoid.
David Kane, your article on response rates for the ILCS survey is a furphy, since it ignores cultural reasons for high response rates. Unless one accepts that thoroughly prepared and trained interviewers in the West could achieve similar response rates, there has to be something else driving the response rates in Iraq. Since the basis of your argument is that a response rate of 98.5% is impossible, you seem to accept that merely having a thoroughly managed survey collection system is not enough. In any case, I am not going to argue over that because it has been done elsewhere, and you raised it initially along with your fraud accusations, which you still insinuate but are not so stupid as to put directly anymore.
As far as I can tell, your vignette about L2 does not contain any information on whether or not the L1 data could be used to identify individuals. Identifiability doesn't just mean "the database contains the address of the house". Data is considered to enable identification if, for example, your home happens to be the only home in the area which experienced 7 deaths. I don't expect you to understand this David because you have been consistently ignorant about every aspect of these survey designs.
David, just 2 months ago I was approached by a nice researcher asking for data from one of my papers. Even though the data cannot identify anyone (it's aggregate data at the state level), has been plotted in my paper (so could probably be reconstructed with some accuracy) and is from a public institution, my institutional agreements prevented me from releasing this data to the researcher even though what they wanted to do with it was interesting (as opposed to, say, mendacious). By your lights I am a fraud or a liar, with something to hide. Which just goes to show that you know nothing about research outside your field.
That would be a stupid assumption, and I recommend no-one make it.
Finally David, your link to that article on replication is instructive and disingenuous. It is instructive because the author argues that replication should hold for all articles, yet you seem to require it only of the lancet survey. Why? And it is disingenuous because (as you keep avoiding recognising) the failure of replication is largely due to your inability to do the maths, and there is no reason to think if you had the data you would be able to replicate anything, no matter the accuracy of the dataset.
David, re:88, it's been a while since I studied the effect of missing data but I would suggest that your question is about a fundamental problem of missing data which is independent of the particular statistic you are studying. If the missingness is related to the outcome, then all sample statistics will be biassed (so your mean would be biassed just as the sum would be). From memory this bias can be in any direction (i.e. towards or away from the null).
If the missingness is independent of the outcome, then in a proper random sample there should be no bias (that's why we use random samples, right?) and the sum should be fine, but the mean is still wrong because it is not calculating the total mortality in the sample. I seem to recall that in non-random samples, missingness independent of outcome produces a bias which is always towards the null hypothesis.
It's been a while since I read anything about that issue though, so I don't think you should take my word on it. Read a basic epidemiology textbook, they always have a chapter on the effect of missing data.
But that is all I am going to say on whether the fundamental method of calculating crude mortality ratios is right or wrong. Go argue it with whoever invented them.
Harald,
The "proof" analogy is a poor one in this case (Sortition's remark "you might as well suggest that divulging proofs of theorems risks your career because it lets the competition know too much" ).
It is very possible (as I explained above) to provide in software documentation (ie, higher level form) everything that is needed to reproduce results -- ie, without providing the actual source code.
Besides, lots of mathematical proofs do not include every last step. The assumption is commonly made that the ones reading the proof will be "skilled in the art" -- ie, have enough familiarity with the field to fill in the missing steps for themselves. Some (particularly novices) may not like that but it does not render the proof invalid.
Even if I agreed with the idea of providing the source code, I would not think that "sending the code off to CS grad students to have them check it over" is really a good way to address the issue, however.
Unless the CS students also had a background in the area treated by the code, I'm not really convinced they would be able to figure out whether the code does what it is supposed to do. I'd also have to say that doing so would actually increase the chance that the code would end up freely distributed (unless that is what you are after, of course).
SG writes:
Untrue! There are many occasions when honest researchers are not allowed to release data even when, as in your case, they want to. You are neither a fraud nor a liar.
However, the authors of L2 (and, really, I think that Les Roberts is the malefactor here) are behaving ridiculously. They give the L2 data to me and a dozen others but not to Spagat et al. There is no excuse for this. I have never heard of a similar case, of researchers sharing data with one critic but not another. Countre-examples welcome!
Now, with L1, things are different. Certainly, the authors could have released the data from L1 in the same format as L2, protecting everyone's identity. They (again, I think that this is Roberts) chose not to. At this point, according to Roberts, the data is no longer available so it is not clear that, even if a honest researcher like Burnham wanted to share the data, he could.
Again, after maining e-mails with several of the authors, I am fairly certain that the restrictions on data-sharing for L1 are no more strict that those for L2. No one has published anything to suggest otherwise.
David Kane,
Spagat's thesis is "Main Street Bias". The only way to test "Main Street Bias" is by getting the address of the sample records. Do you understand how it is impossible for Roberts and Burnham to give this information away?
not if there are smaller cluster sizes, or the specific nature of data with many fallujah-related deaths means that some households in Fallujah could be identified. Or do you think that the authors have ethics approval to identify individuals who took part in the survey?
But again this is irrelevant. Would you release data to another researcher (e.g. David Kane), knowing that researcher was going to fail at the first technical hurdle, but blame their incomprehension on you? I know I wouldn't.
As penance for my sins, I have written up a brief discussion on non-response which explains why the formula used in L1 is not as obviously correct as Robert Chung, SG and others like to pretend. Any comments on that should be directed to this thread on Deltoid.
penance: voluntary self-punishment in order to atone for some wrongdoing
HINT: in general, a PENANCE seems to be something that HARMS you. wou wrote a COMPURGATION or an EXCULPATION.
more and more i arrive at the conclusion, that you simply lack basic DECENCY.
i have some serious doubts about the things that you wrote in it as well, but there are people with more knowledge around to correct you AGAIN.
but a simple point can be cleared by taking a look at the lancet paper:
Houses with no one home were
skipped and not revisited, with the interviewers
continuing in every cluster until they had interviewed
30 households. Survey team leaders were asked to record
the number of households that were not home at the
time of the visit to every cluster.
http://www.zmag.org/lancet.pdf
and
In every cluster,
queries were made about any household that had been
present during the survey period that had ceased to exist
because all members had died or left. Empty houses or
those that refused to participate were passed over until
40 households had been interviewed in all locations.
http://www.thelancet.com/webfiles/images/journals/lancet/s0140673606694…
hm, posted too soon. the two quotes above were meant as an answer to Davids claim that "Such a proceedure ignores the fact that non-response varies across clusters."
http://lancetiraq.blogspot.com/2007/09/missing-data.html
While the (endless? -- at least in some people's minds) debate rages on about whether Lancet1(2) belong in the "Debunked" basket, the "To Debunk" basket is overflowing to the roof ...
According to a recently released Oxfam report:
Debunking waits for no one.
What's the holdup? Get on it, man!
Otherwise, people might begin to think (falsely, of course) that Iraq is actually experiencing a truly monstrous humanitarian crisis.
From David Kane's *essay* on why the L2 response rate is not comparable to the ILCS/UNDP one:
> *In other words, ILCS interviewers went back to the sample households again and again and again.* This is quite different from the procedure in Lancet II. In that case, a cluster was visited on just one day. *In fact, it appears that houses were just checked one time. What good fortune that there was almost always someone (head of house or spouse) at home!*
Seriously, that's the argument? First of all, it is *not* the case that in the ILCS survey, "the interviewers went back to the sample households again and again and again" *as part of their design*. They did it **only when there was indication of problems in the data they collected**. From page 50 of the Analytical report:
> "*Nevertheless, when first estimated, the mortality rates turned out to be lower than those published here. Therefore, it was decided to conduct control interviews in order to check if all births and deaths were recorded. First, a sample of 500 households in Baghdad that had already been interviewed were interviewed again. The questionnaire used consisted of just the birth history and parts of the labour force section. _Once it turned out that there were indeed some omissions of births and deaths, it was decided to re-interview all households again with the small questionnaire._*"
Which given the scope of their research, was much more likely to happen. Their interviews lasted almost an hour and a half, and covered *a lot* of different issues, and were conducted by Western interviewers.
L2 was much shorter, dealt specifically with mortality figures and was conducted by Arabic speaking Iraqis.
Claiming that one is more thorough than the other without making reference to their different scopes and objectives is very very misleading. In fact, one could easily claim the reverse of what you did: the ILCS found out that using Western interviewers and long interviews produced way too conservative mortality figures. What did they do to solve it? They have redone the interviews with a shorter and more focused survey. L2 improved on the ILCS by using an even shorter more focused interview to begin with and used native interviewers. If anything, they should give more accurate mortality figures. So which one is "more thorough"?
But most importantly, there is *absolutely nothing* in the ILCS report that suggests their response rate was calculated any differently from the L2, so any implications on your part have to carry the big disclaimer "I have absolutely no grounds to even make that speculation".
As for the attempted sarcasm in "*What good fortune that there was almost always someone (head of house or spouse) at home!*"
**Parent's presence in household (p.27 ILCS)**
- Both parents: **93.4**
- Mother only: 1.3
- Father only: 4.5
- Both not present: 0.8
So most households have both parents at home. What is the employment rate?
- Men (p.107): 69% employed, **31% unemployed**
- Women (p. 108): 13% employed, **87% unemployed**
So unemployement IS extremely high, and MOST women are NOT employed to begin with. And keep in mind this report is from 2004, before the civil war started big time.
Is that so surprising that most households visited would have someone there?
> It is very possible (as I explained above) to provide in software documentation (ie, higher level form) everything that is needed to reproduce results -- ie, without providing the actual source code.
It is also the case that in theory the statement of a theorem is all you need in order to know whether it is true or not, since the reader (being competent enough) should be able with some effort to repeat (and in that way indepedently verify) the steps taken in the original proof. In this sense, the statement of the theorem alone can be considered sufficient documentation of the proof.
> Besides, lots of mathematical proofs do not include every last step. The assumption is commonly made that the ones reading the proof will be "skilled in the art" -- ie, have enough familiarity with the field to fill in the missing steps for themselves. Some (particularly novices) may not like that but it does not render the proof invalid.
Are you implying that the reason published mathematical proofs do not include "every last step" is to protect the competitive advantage of the author or to challenge the reader to retrace the steps of the author?
Far from it. The author of a paper containing a proof should attempt to write the proof at a level which is comfortable for the readers: enough detail to follow the proof, not too much detail to obscure the proof or bore the reader.
The reason that not "every last step" is included, is because there is no level of proof at which it can be said to include every last step. Unless a machine verifiable proof is provided, one can always doubt any step and ask for more detail. If a machine verifiable proof is available (which would involve an unimaginable amount of work in most cases), then by all means it would be very useful for the author to publish that proof, in addition to the human-readable proof.
Mathematics is exceptional in two ways, first, there is no experimental data, second all proofs are gone through line by line by expert referees (which is why publication delays are huge).
Which brings me to my second example the sign error in Christy and Spencer's algorithm for the Microwave Sounder Unit data discovered by the RSS team. I would contend that this agrees with my earlier assertion that errors in code are best discovered after replication fails by experts.
The problem here is that when such cases become entangled in policy it is difficult to allow the necessary time. Sturgeons Law says that 90% of anything is crap.
Rabett's corollaries are that 99% of the errors in crap coding in crap papers should be ignored. Most will be caught by referees sounding the bullcrap alarm. The remaining few will be found and corrected when someone gives a crap. Otherwise referees will spend their lives pounding sand.
As a further example why detailing is practically impossible, you can look at lab experiments. You could possibly detail every nut and bolt in a setup, and still have others fail to replicate the experiment when building an equipment clone. (Which, as noted, is an uninformative method of replication.)
Why? Because the material used may have been special by being defect; chemicals tainted, cell isolates impure, et cetera. What you can do is to save some amounts of non-standard ingredients so if someone can't repeat your experiment you can go back and check what went wrong. And if it is a new effect that was presented you can help other labs by disclosing the "nut and bolts" description.
SG writes:
I have communicated with Spagat on this. Although it is true that he and his team would like enough detail to test MSB, they would be eager to just start with the data that has been released to people like me. In other words, Roberts et al refuse to give Spagat even the data that they give to other people. Again, I believe that this is unprecedented. At least, no one in the Deltoid community has cited a similar example.
Also, Spagat and others are not seeking addresses since the Lancet authors report that all addresses were destroyed by the survey teams even before they left each neighborhood. There is no address data to look at.
So David, you have finally admitted something - Spagat can't use the data to check their thesis for confidentiality reasons. But you still don't get the whole story do you? You say
Do I need to put this in capital letters and shove it up your arse? It is possible to identify individuals without using their address. All you need is a distinctive house in a small area, and the locals can identify it. A distinctive house can be the only house in the town with a household member who was killed by a bomb, or it can be the only house with a lot of immigrant family members. All that information is contained in the data. It doesn't matter that it is also in L2 - if L1 has even one cluster where this identification is possible, you don't get the data.
As for not giving Spagat the same data as you - if only Roberts and Burnham have the right to give Spagat that data, why have you published it at CRAN? And if they don't reserve that right for themselves, why do you complain?
(And why do you refuse to answer so many of my questions?)
(Also, I am pretty confident that researchers I have met will not share data with people they don't trust. I generally don't hear about it because the usual run of mendacious, nasty researchers don't have as much balls as you or Spagat, and don't ask for the data in the first place).
"Sortition said: "It is also the case that in theory the statement of a theorem is all you need in order to know whether it is true or not, since the reader (being competent enough) should be able with some effort to repeat (and in that way indepedently verify) the steps taken in the original proof"
It's simply ridiculous to claim that is the same as "It is very possible (as I explained above) to provide in software documentation (ie, higher level form) everything that is needed to reproduce results -- ie, without providing the actual source code."
I explained above why: software documentation gives you all the necessary steps to produce the results.
Sortition continued:
"Are you implying that the reason published mathematical proofs do not include "every last step" is to protect the competitive advantage of the author or to challenge the reader to retrace the steps of the author?"
That was not at all what I was claiming. All I was saying was that even mathematical proofs don't give every last step. My explanation gave the very reason for that. If the person reading the proof is familiar with the subject, they don't need every last step (as a novice would).
Those commenters opposing publishing code suggest that as long as the published work is reproducible by competent readers, it is not incumbent upon the authors to make it _easy_ for the readers to do so.
My position is that it is the duty of authors to make reproduction of their work and consequent research by their readers as easy as is reasonably possible. Any code used by the authors would therefore naturally be part of a well-written paper.
I claim that accepting the proposed policy of allowing to make reproduction difficult, as long as it is at all possible, would have absurd implications. That is the purpose of the example of theorems without proofs - reproduction is possible, but very difficult.
Even if we reject this example as extreme or "ridiculous", as does JB, the implication remains: a policy that allows the author to make reproduction difficult opens a Pandora's box. How difficult is too difficult? What if the author does not provide a proof, but instead provides some hints as to how the proof goes - is that acceptable? Or, to take a completely different example, what if an author provides parts his paper in a disemvowelled version only?
No - it is the role of the scientist to be clear, open and instructive. Withholding information (code, or anything else that is of relevance to the research) without very good reason, is unscientific and should not be acceptable.
Quite frankly, that doesn't sound like any paper I know of, where a lot of effort has gone into structuring and paring down unnecessary details to make the chain of evidence strong and easy to grasp.
Detail can and should be provided at request, unless these special reasons (confidentiality, disclosure, competition) preclude.
The science goes into the ability to repeat and retest, not into stamp collecting detail.
That said, there are open access efforts to enable publishing raw data and derivative graphs, which are the kind of detail you would like to have access to as basis for new research.
I took it as clear that some things, like code, are not part of the body of the paper but are available as supplementary material.
Oh, I see. Well, supplements typically contain long original derivations, for example if a code uses a new algorithm that needs description for future reference or so.
I never add the drawings of equipment to experimental papers, and likewise I wouldn't like to see the software code of R or similar codes.
I'm reminded of a discussion on The Panda's Thumb, there the result of a genomic analysis looked so corny for a specialist on a protein assembly that he teased out that the researchers had used, erroneously there, default settings for the statistical analysis.
Nobody claimed the researchers had withhold usual detail (used settings) or saw something inappropriate, and they corrected their analysis. Just as for Robert above, the experts were used to the analysis and didn't expect the paper to be written for non-experts, so didn't complain about lacking a description of settings for a common software.
In any case, there are a lot of problematics involved in claiming general rules on paper presentations. It differs between areas. That is why I stressed the results (repeatability) over formalism (details). I'm not sure any one strategy is "correct", but I'm pretty sure what scientists (at least in my area) do in practice.
(Everyone else, this concerns comment 88 and is irrelevant, so don't read it - for David's eyes only)
David, I just had a look at the problem you describe in comment 88 (on your separate blog) and your method of means becomes more and more biassed as the bias in the missing values increases. Here is some r code you can try to show it to yourself:
1) suppose 10 clusters all with a true death rate of 1/10, suppose that in all clusters 110 individuals sampled and 11 deaths observed. In 8 clusters there are 10 missing observations, all with no deaths; in 2 clusters there are 50 misisng observations, all with no deaths.
construction:
>vvec2<-cbind(rep(11,10),c(rep(100,8),rep(60,2)))
> vvec2
[,1] [,2]
[1,] 11 100
[2,] 11 100
[3,] 11 100
[4,] 11 100
[5,] 11 100
[6,] 11 100
[7,] 11 100
[8,] 11 100
[9,] 11 60
[10,] 11 60
test David's mean:
> mean(vvec2[,1]/vvec2[,2])
[1] 0.1246667
calculate the correct way:
> sum(vvec2[,1])/sum(vvec2[,2])
[1] 0.1195652
so now the bias is 12.5% for your method and 12% for the correct method.
Then repeat with 5 clusters having 50 missing values, and the same true death rate (code omitted, too boring to copy and paste), result:
David's method:
[1] 0.1466667
Proper method:
[1] 0.1375
so now the biasses are 15% and 14% respectively - bias has increased for the incorrect method.
Note how both methods are biassed against the null, but the mean method is more biassed.
#102 Kane:
Confidentiality aside the problem is Spagat has a clear agenda to rubbish the lancet study and zero expertise in the field:
Considering this why would you release anything to someone who has no interest in truth, science, error checking and no experience in said discipline who's agenda is clearly to rubbish your study to great fanfares despite the evidence. Truthfully I was disappointed they gave in and distributed anything at all to you vultures.
No what is 'unprecedented' is the lengths that individuals and groups such as Spagat and yourself with little or no experience in the field have gone to to rubbish this study for entirely political reasons. If this engenders 'unprecedented' reactions then we should be largely unsurprised. In any case its such a disengenuous, non-sequitur thst your implications here, again of malfeasance and fraud on the part of the authors, is out of line and entirely speculative. Its mud slinging, although admittedly, considering how thoroughly your attempt to debunk the study has been destroyed here that is all you have left.
i think it s rather difficult to discuss "more openess" in science, with David around.
just take a look at what he did with data made available to him:
However, the data shows that only 29 of 47 clusters featured exactly 40
interviews. The following table shows the number of clusters for each total
number of houses interviewed:
33 36 38 39 40 41
1 2 5 8 29 2
http://www.bioinformatics.csiro.au/CRAN/doc/vignettes/lancet.iraqmortal…
his interpretation given online later looks like this:
Such a proceedure ignores the fact that non-response varies across clusters.
Consider a simple example in which you have two clusters with 50 attempted interviews in each using a one year look-back period. In cluster A, you interview all 50 households. There are 10 people in each house and a total of 20 deaths. The CMR is cluster A is then 4% (20 deaths divided by 500 person-years). But, in cluster B, only 10 households agree to be interviewed. The other 40 refuse. There are also 10 people in each of the 10 households. There is one death, giving a CMR of 1% for cluster B.
http://lancetiraq.blogspot.com/2007/09/missing-data.html
his example uses a 80% missing responses in 50% of the clusters.
the Lancet paper had less that 5% missing responses (on average) in less than 40% of the clusters.
in short, this example has nothing to do with the lancet reality and simply is a distortion of facts.
and David wrote this misleading example in a post, that he considers his "mea culpa" for having been shown to lack basic understanding!
while i certainely support more openess in the science community, individuals lie David Kane make me serious doubt the effect of it.
sod,
My example was purposely extreme to illustrate the underlying point. It was intended for layman, like, say, Donald Johnson, who want some intuition for why different methods for calculating CMR might lead to different answers.
SG,
You are obviously a serious fellow and I have wanted to answer your questions. If I have missed some, my apologies. You write:
Of course! My only claim, and I am pretty sure that the Lancet authors would agree, is that they have taken care to ensure that this is impossible for the data which they released for L2 and that similar care could be taken for the data for L1. None of the authors have disputed this.
Now, it may be impossible to provide data at enough detail to both satisfy Spagat and maintain confidentiality. But that is not the fight we are having today. The fight today is: Why not give Spagat et al the same data that they give to me (and a dozen others)?
Have you read my description of the data? There is no information about specific towns, except for Falluja and Baghdad, for precisely the reasons you give.
I have only published the data for L1 on CRAN, data that Tim placed in the public domain when he posted it (without objection from the L1 authors, I assume) on Deltoid. I did not post the data for L2 on CRAN (or anywhere else) because the agreement I signed prevents me from doing so. I did provide tools for working with the data for those who have access to it.
Let me know if I have missed any.
Why do you restrict this to just me and Spagat? There are at least 4 co-authors of Spagat (Neil F. Johnson, Sean Gourley, Jukka-Pekka Onnela and Gesine Reinert) who would like access to the data. Are they also "mendacious, nasty researchers?" Just asking!
In post #88 above, [David Kane](http://www.google.com/url?sa=t&ct=res&cd=1&url=http%3A%2F%2Fwww.apa.org…), trapped, desperate, and gnawing his leg off, wrote:
Dude, you're arguing that the crude mortality rate shouldn't be the crude mortality rate. When you're done with that, can you try arguing that 2+2=4 isn't as obviously correct as I like to pretend? I think that'd be kinda entertaining, too.
"Those commenters opposing publishing code suggest that as long as the published work is reproducible by competent readers, it is not incumbent upon the authors to make it easy for the readers to do so."
No, that's not at all what I have been saying. This is not about making things "difficult" for those who would repeat the results.
That I don't give you my actual source code does not mean repeating the results will necessarily be "difficult" if all the important steps have been laid out in front of you (in documentation).
Sometimes (often?) it is actually more difficult to figure out what someone else has done than to simply solve the problem for oneself.
Often, it is fairly easy to quickly "hack" a computer program together that solves the same problem as a very elegant program that took considerable time -- and that can be extended (or perhaps already is) to do many other things besides the problem at hand (Wolfram's Mathematica comes to mind as an example of the latter).
The first program was easy, the second relatively difficult. The fact that I do not provide the source code for the second (Mathematica) has little to do with how difficult the first task is, particularly when the really/i> difficult part -- the algorithm and its application to the case at hand (including critical implementation steps) -- have already been documented and provided by me.
Sorry Sortition, authors do not have a duty to hold anyone's hand, if nothing else, no one has the time. Look at the effort that a clueless David Kane has extracted here there and everywhere. Those who know, in the normal course of things would have simply ignored him after his initial effort (it was excised with extreme prejudice from the web site where it was originally published). However Kane has used politically motivated allies to keep the waters boiling and cost everyone a tremendous amount of effort. See McKitrick.
JB, from sad experience we all know that code is not self documenting and STEM graduate students do not believe in documenting their code. Mostly you ARE better off with the description of the algorithm in the paper. Again, this is a fight between what should be and what is.
I am glad to welcome Robert Chung back to the discussion. SG, in comment 73 above, claimed that the confidence intervals for the CMR estimates in L1 could not be calculated without "data to the level of the household, which we don't have." Indeed. But Robert has argued, above, that he can replicate the CMR confidence intervals even though all we have access to is the cluster-level summaries. Who is right? I think SG.
David
As you have a blog on Lancet/Iraq, why don't you simply open the posts there for comment? Provided you are willing to do so with little or no moderation, that would seem to be an equally valid location for such discussions.
Will you accept Robert's bet this time before he cleans your clock in public?
So a thread that begins with David Kane saying to Robert Chung: "Anyway, it seems clear to me now that you are bluffing" has now after 117 comments arrived at the point where the same David Kane, now with lashings more egg on his face, saying exactly the same thing about another issue. David, it's reasonably clear what's going on here. You're trying to get Robert to do your homework for you. He isn't going to. He just might if you were to place a bet, but clearly you are too shrewd to do that.
As a way out of this impasse, I suggest you tell us why you hold the view you do. Have you done any exercises which lead you to believe that the CIs can't be constructed from the available data? If so, what have you tried? Have you tried to construct a proof of insufficiency? More bluntly, have you bothered your arse doing any work at all or are you simply relying on your undoubted talent for squeezing information out of people? That talent has served you well for getting your hands on data but it has exposed the fact that you don't really have much idea what to do with it once you have it.
richard asks:
I closed comments on that entry on purpose as it seems rude to shift the conversation somewhere else than Deltoid. For those interested in my posts on related topics, here, here and here are the three most recent.
As to those suggesting a bet, I agree! I have written to Tim to see if he would be willing to host/judge such a context. Basic rules would require that someone replicate the estimates and confidence intervals for CMRs, relative risks and excess deaths printed in L1 using the available data. SG and Robert have already done some of the work here, but I continue to believe that the confidence intervals can't be replicated. I hope that Tim will host/judge the contest.
Let me second Kevin Donaghue on his suggestion:
> *I suggest you tell us why you [David Kane] hold the view you do.*
David Kane suspected L1 and L2 results (he called fraud on the authors at least once).
He is not a biostatistician or epidemiologist, and as became clear in this thread, his suspicions cannot have arisen because his technical expertise allowed him to spot a critical problem with both studies. So far, he hasn't.
His suspicions might have arisen from the fact that the authors are reluctant to release all their data together with their source code to other interested researchers.
However, he has been informed by practicing researchers that this in fact is not uncommon with public health data, and the authors' behavior do not deviate from standard practice in the field (whether this is a desirable state of affairs is another issue, but it is clear that the authors' cannot be faulted for things being this way).
Is this a fair summary?
So, what other reasons do you have to doubt L1 and L2, David?
We know they can't be technical, and they can't be any suspicious behavior from the researchers, so what are they?
Eli:
> Sorry Sortition, authors do not have a duty to hold anyone's hand, if nothing else, no one has the time.
I don't see publishing code as holding someone's hand. It is a reasonably easy way to help your audience understand your work, verify it, and use it as basis for further research. It is not intended to satisfy clueless hacks like Kane.
I don't see why "no one has the time" to publish code. You might as well say that no one has the time to write papers. Yes, it takes time, but it also serves a useful purpose. The effort and time spent on publishing the code should not be out of proportion to the effort of doing the research or writing the paper.
JB:
You wrote (#114):
>> Those commenters opposing publishing code suggest that as long as the published work is reproducible by competent readers, it is not incumbent upon the authors to make it easy for the readers to do so.
> No, that's not at all what I have been saying.
Maybe I didn't understand you, but I thought this is exactly what you said in #31:
>> So the idea is that you give proper documentation so that your competitors could reproduce your work, but you don't give the code so that it is not too easy for them to do it?'
> That is precisely it.
"as it seems rude to shift the conversation somewhere else than Deltoid."
Like to Malkin?
Exploded head has a great idea.
re: #122, this has never been about science, but ideology. Kane is a gung-ho, pro-war, right-wing ideologue. He called "fraud" before any sort of serious thought. He had his post taken down on the Harvard stats web site. And now everything else is simply an effort to provide the smallest bit of rationale for that obviously wrong, and wrong-headed, assertion. His disingenuous invocations of "how science is done" has nothing to do with science. He will never give up, he will never listen to reason, he will, in his own mind, always be right. It is about confirmation of steadfast bias, not falsification of hypothesis.
"In his spare time [David Kane] helps people believe that violence in Iraq could not possibly be as bad as the Lancet study demonstrated."
Had David been an adult in 1967, he would probably be publishing papers claiming that napalm burns were only slightly painful.
Had David been an adult in 1939, he would probably be defending Germany's response to Poland's communist-inspired attack on them.
And in 1946, just imagine what might've happened if he and David Irving had been drinking buddies ...
David at 117: of course you think I'm right, it suits you. I bow to Robert's superior experience, intellect and humour on this one.
I'm off to teh Japan Statistical Association conference in Kobe, so likely won't have anything to add to this thread of doom until Monday.
sod, My example was purposely extreme to illustrate the underlying point. It was intended for layman, like, say, Donald Johnson, who want some intuition for why different methods for calculating CMR might lead to different answers.
while i enjoy your "layman" arguments, it is NOT what you did in your article.
instead you write:
Although I am a layman when it comes to demography, it seems obvious that any statistican would question whether just adding up all the deaths and dividing by person-months is the best way to estimate the crude mortality rate for Iraq. Such a proceedure ignores the fact that non-response varies across clusters.
you are making a very strong claim about the case of Iraq.
nowhere do you explain, that the situation of "lack of response" in Iraq is on a completely different order of magnitude.
Ignoring non-response causes you to weigh clusters with higher-response rates more heavily even though, a priori, there is no particularly good reason to do so.
a priori, there is NOT even a good reason, why you want to discuss the non-issue of non-response rates in the lancet iraq study. but you decided to write a piece about this anyway, one including a completely misleading example!
even your disclaimer, does not tell the full truth!
Indeed, the differences in the two approaches for the Lancet data are even smaller.
again: the effect will be smaller my MAGNITUDES!
here is the link again:
http://lancetiraq.blogspot.com/2007/09/missing-data.html
I think Kevin is correct. All David Kane is doing is to get others to do the job for him. He throws in a claim and waits for the discussion to see what he can get out to use in his politically motivated 'articles'. And if he gets intellectually spanked, he sends a 'thank you for the discussion' note to look like a nice and honest guy. Look, he's started by saying he could 'bet' Robert couldn't replicate the data, to later say that he wasn't willing to 'bet' because he 'knew' someone could replicate the data. David Kane is simply a dishonest guy with a political agenda.
"You know when you said you think of yourself more as a statistician than a political scientist? I'm guessing a lot of statisticians are asking "why us?" and a lot of political scientists are high-fivin'."
Oh, so funny. I have to remind myself to look at their CV the next time I ask a statistician to check some work rather than just assume that anyone who calls themselves a statistician must know what they are doing.
Actually, this leads to useful question: is there a simple way for a complete non-expert such as myself to estimate a statistician's reliability?
You mean like calculating the odds?
> Actually, this leads to useful question: is there a simple way for a complete non-expert such as myself to estimate a statistician's reliability?
The answer, I believe, is "no".
This is one particular case of a general problem that is rarely discussed: many aspects of reality are not obvious. There are many things about which there is no way to form an informed opinion without putting effort into finding out the facts.
You either have to believe the accepted wisdom or put in the time and effort to do some independent research.
Oddly enough, this is the topic of David's dissertation, "Disagreement". The answer, shockingly enough, is to increase the confidence interval and simulate parametrically. Breathtaking...I might have used a flat prior and layered hyperparameters, but that's just me. Of course, you could also use the outcome of experimental bets (hmmm) to figure out that uncertainty...as in Sarin and Wakker "Revealed Likelihood and Knightian Uncertainty", which oddly enough David does not cite.
Of course I jest. The only way to know is to do the work, or to rely upon (noisy) external signals, like tenure at an Ivy League school, publication record, and a PhD from a reputable school in the actual field of record. This is why when I see an infomercial on TV about male enhancement or natural cures I don't believe the PhD "doctor of homeopathy" who's telling me it works...even though he has a blog.
"Actually, this leads to useful question: is there a simple way for a complete non-expert such as myself to estimate a statistician's reliability?"
Yes, there are, but they would be frowned at by some statisticians. Look at their politics, look who they write for, look what other statisticians are saying. Look what they have been wrong and right about in the past.
In short, google them and make up an opinion on what you see.
I'm not saying it's always a good way, but it is a way. I say it's better than assuming all specialists are equally reliable.
JG: In fact I am after public and distributable code (like for instance the code for R is), but I'm also interested in seeing code published along with documentation. Yes, as Rabett says, serious implementation errors will be discovered on attempts at replication, but that's the hard and expensive way of doing it. If the documentation is good, checking an implementation's compliance with it should not require very much domain knowledge.
I was aware that some huge, important programs like climate models are written in Fortran, in part for performance reasons. What shocked me was that many people apparently still use Fortran numerical libraries directly in cases where packages like R or Mathematica would be appropriate.
Errors will creep in that way. I suspect you underestimate how easy it is to make implementation errors, and how long they can go undetected.
Why don't we ask someone with long experience in detecting them whether it's easier to find implementation errors by inspection or by reimplementation and comparison? Like, say, a computer science lecturer?
"Why don't we ask someone with long experience in detecting them whether it's easier to find implementation errors by inspection or by reimplementation and comparison? Like, say, a computer science lecturer?"
What's important isn't the implementation, all you need is the algorithm, detailed to a greater or lesser degree.
As a simple example, you don't need someone's sort code to figure out if the output is correct. You don't even need to use the same sort algorithm. You just need the input data and the parameters (ascending, descending, etc). If the other guy used a bubble sort, and you use a quicksort, the only difference should be how long the sort takes, which isn't the issue. The output should be the same. Same procedure ('ascending sort') same inputs ('z','b','x','d'), same result ('b','d','x','z').
Likewise, if someone says they did an FFT on some data and produced result X, you don't need to have their FFT code, you need a way to run an FFT with the same inputs. It should produce the same answer.
If someone says they did an NPV calculation, you don't need to see their code, you just look at the inputs and output and run it through the implementation of your choice.
What you want is a high level description, "Given this data, we ran a ascending sort, then an FFT, then an NPV and arrived at these results." Given that kind of data (with a little more detail about function parameters) you should be able to check their work. The source code would be superfluous.
The *actual code* used by a given researcher might well include a lot of stuff that is irrelevant to the specific problem, but is used in their work in general. And it might have dependencies on various custom utility libraries built at their institution, or highly optimized commercial libraries, which may have complicated publishing rights. The code used isn't necessarily a standalone file of sourcecode that depends only on standard libraries.
In order to publish the code as you wish they may have to either publish the whole kit and caboodle (not what you'd want) or they'd have to extract only the specific code relevant to the particular issue, from wherever that code had lived before, replace proprietary or rights-constrained implementations with public-domain implementations where necessary, boil it down to the bare minimum, and then publish. This can be quite a large undertaking.
Harald - I think I'd trust a Fortran numerical library that's probably been around since the mid-70's, probably used continuously since then more than I'd trust an R or Mathematica routine and, if my own experience is anything to rely on, I'd trust a physicist to implement what they intend in Fortran more reliably than they would in Mathematica.
I've worked as a physical scientist for 15 years, most of that time as an academic, quite a lot of code gets shared, or made public by scientists but it's never been a requirement for publication and to my mind there's never been a demand for it amongst academics. If you're doing research in a numerate field, then the chances are you're going to re-implement stuff as a learning exercise. This has the benefit of flaggings typos in papers and revealing any "skeletons in the closet".
Sortition wrote: " Any code used by the authors would therefore naturally be part of a well-written paper."
That code will become obsolete rather quickly. Some of it will come from obscure languages, or specialized proprietary products that never quite took off.
A paper accompanied by source code to drive the twin i860 CPUs and 56001 DSP processor on a specialized Ariel expansion card for the 1990s NeXT Cube isn't going to be very useful to anyone these days.
A paper accompanied by mathematical formulae and descriptions of the algorithms used would be more useful, because they could be reimplemented on modern hardware and software, since today's hardware probably doesn't need that kind of specialized coprocessor for adequate performance.
Sortition writes: "It is simply a matter of making it a requirement for publication. People find the time to handle all the other requirements of publication - I see no reason why this would be any different."
So, say, neuroscience researchers will need to submit their monkey to the journal, so other researchers can use it?
Robert wrote: "You're drubbed, whupped, and schooled. You deserve all of it. You need to read this."
Heh. As soon as I clicked on that link I knew what would be on the other end even before it loaded.
In other news, the US is now mounting nuclear cruise missiles on B52s headed for Barksdale AFB, which happens to be a staging point for the Middle East.
http://www.timesonline.co.uk/tol/news/world/us_and_americas/article2396…
The "liberal media" hasn't put that together yet, being (slightly) fixated on the spectre of armed nukes being flown across the US.
Hmm. The underlines in the url get converted to italics. Let's try again with <
on the Topic of including code, there s big news.
Hansen has released the code to reproduce his results.
http://data.giss.nasa.gov/gistemp/sources/
it looks (as predicted!) as if the code is rather ugly.
The subdirectories contain software which you will need to compile, and in some cases install at particular locations on your computer. These include FORTRAN programs and C extensions to Python programs. Some Python programs make use of Berkeley DB files.
and he has asked for some weeks to "clear it up".
there is a huge celebration over at climateaudit.
i m slightly worried that every error found in the code, resulting in -0.02 correction in a year, will lead to headlines:
global warming a computer error!
but we shall see.
Sortition: "This is one particular case of a general problem that is rarely discussed: many aspects of reality are not obvious. There are many things about which there is no way to form an informed opinion without putting effort into finding out the facts.
You either have to believe the accepted wisdom or put in the time and effort to do some independent research."
Completely unhelpful reply, of course. The "accepted wisdom" is that anyone who calls themselves a statistician and who appears to have the appropriate degrees from well-known schools can be trusted to do simple statistical work. If I wanted to do the work myself, I wouldn't be trying to hire someone to do it. And of course it's impossible to do all such work myself, unless I want to be my own doctor, lawyer, etc.
Thursby is right about the noisy external signals of professional competence, but they are indeed noisy. I was hoping that people who were actually statisticians might know some kind of rule-of-thumb way of evaluating it that might help novices.
I'm left with Harold K's:
"Yes, there are, but they would be frowned at by some statisticians. Look at their politics, look who they write for, look what other statisticians are saying. Look what they have been wrong and right about in the past."
I think that the simplest rule of thumb is that anyone who has ever written for the right wing, in general, is incompetent. I might miss some competent people this way, but the downside cost of getting an incompetent one is very high.
Rich Puchalsky:
> Sortition: "This is one particular case of a general problem that is rarely discussed: many aspects of reality are not obvious. There are many things about which there is no way to form an informed opinion without putting effort into finding out the facts. You either have to believe the accepted wisdom or put in the time and effort to do some independent research."
> Completely unhelpful reply, of course.
Sorry. Facts can be inconvenient at times, but that's not a reason to wish them away.
> And of course it's impossible to do all such work myself, unless I want to be my own doctor, lawyer, etc.
You can't check everything yourself, so you have to pick and choose. Doing the picking may not be that easy either, of course. Again, sorry, but that's how it is.
"Again, sorry, but that's how it is."
Well, I know that this is a side-path, but that generally just does not seem true. Most knowledge is statistical. You're treating "an informed opinion" as if there are only two kinds of opinions, informed and uninformed. But there are all kinds of heuristics that can help people make better decisions of this kind. For instance, let's say that someone wants to pick out a medical doctor. If they have very little time, I'd say that they should see whether the doctors they can choose from are board-certified (in the U.S., anyway) and in what. If they have more time, they can ask different experts to recommend particular people in their area who are good at particular subfields of medicine. None of these steps amounts to "doing some independent research" really; each of them will lead to a substantially better decision on average. All of these kinds of steps benefit from the advice of someone who actually knows the field.
Harald, LINPACK was ok and there are good succesors including those for massively parallel processors. The issue with R and Mathematica is that they are slow.
As a lay person I want to thank everyone for the fascinating discussion. There is just one thing though. You guys do know that David Kane is a troll don't you? There is no argument that you could ever produce that will change his mind or alter his position. All you need to know about what is really going on is in the very first sentence to his "penence" at #88:
"I have been having fun on Deltoid recently"
You don't need to bring in a statistician to understand what is actually going on in this thread, you need a psychotherapist.
> None of these steps amounts to "doing some independent research" really; each of them will lead to a substantially better decision on average.
To me those things _are_ independent research. Every time you put in your time and effort to find out information and evaluate it, it is independent research. I agree completely with your description: there is a ladder of time and effort you can climb, each time investing more time and effort, getting a better understanding of the issues, gradually relying less and less on secondary and tertiary sources and more and more on primary sources. Climbing each rung on this ladder makes your decision more informed and increases the chance that you make a correct decision.
> All of these kinds of steps benefit from the advice of someone who actually knows the field.
I agree, but didn't we start out by trying to find out who can be considered "someone who actually knows the field"? That's part of your research.
That's a bit like Custer asking his aide, "are you SURE those are Sioux warriors slaughtering my troops?"
Bad example, considering that a lot of those "Sioux" warriors were actually Cheyenne . . .
rea wrote: "Bad example, considering that a lot of those "Sioux" warriors were actually Cheyenne . . "
The key point is that the tribe is beside the point - Custer's attention should be on the ongoing slaughter of his troops, not fiddly details about who's doing it.
Likewise, it doesn't really matter if the 'Robert' person sinking an argument is Robert Chung or another Robert. If the assault on the argument stands on its own, who's making it is beside the point.
For people who haven't found their way there yet, the discussion in this thread is nowhere near done and continues here.
Brenda, when you wrote "I want to thank everyone for the fascinating discussion" I assumed you were David Kane for a moment :-)