
Given the study that I’m going to discuss, I can’t help but start out with a brief (for me) reminiscence. Longtime readers know that I graduated from the University of Michigan Medical School in the late 1980s. Back when I attended U. of M., its medical school was considered stodgy and hard core even by 1980s standards. No organ systems approach to education for U. of M.! Oh, no. It didn’t matter that the organ systems approach, in which all classes are organized by organ systems and teach the same organ systems at roughly the same time (e.g., biochemistry teaching the biochemistry of the heart while physiology class teaches the physiology of the heart while anatomy teaches the anatomy of the heart, etc.) was sweeping medical education. Then, just to be hardcore, U. of M. would administer three examinations and a final every term, each of which would be one test testing students on every topic that term. One of the classes spanned the first two years and culminated with a final exam that covered all the material from all two years. Meanwhile, the Department of Internal Medicine was chaired by William Kelley, a hard core academic internist who had been recruited to Michigan in 1975 at age 36 as the youngest chair of medicine in history at the time. While on my internal medicine rotation I remember the trepidation we all felt preparing to present to Dr. Kelly when he did chairman rounds. The Department of Surgery was just as hard core in its dedication to science and the scientific basis of medicine.
There was no “complementary and alternative medicine” (CAM) or “integrative medicine.” There was no “quackademic medicine” (the infiltration of quackery into medical academia).
Of course, I graduated from medical school about a decade before the wave of pseudoscience known as “integrative medicine” swept through medical school, annihilating the line between science and pseudoscience in its wake. Even so, I have a hard time imagining any reaction to the sort of pseudoscience routinely found in medical school other than derision.
How the culture has changed at U. of M. since I was there. For example, there is a program in anthroposophic medicine there. Yes, we’re talking about Rudolf Steiner. There’s also a very active program in integrative medicine there. There’s even a naturopath on staff, Suzanna Zick, ND, MPH. (I can’t help but shake my head at how far my alma mater has fallen.) We’ve met her before, specifically as a co-author of the Society for Integrative Oncology’s clinical practice guidelines for breast cancer care. Here, she is the first author of a study of acupressure for cancer-related fatigue in JAMA Oncology hot off the presses last week.
When I think of acupressure, I like to think of it as acupuncture, only without the needles. It’s based on the same vitalistic concepts as acupuncture, in which qi, or life energy, flows through meridians. Instead of sticking thin needles into specific points along these “meridians” (which, remember, have never been demonstrated to exist and have no anatomical correlates), though, acupressure involves applying physical pressure to these same “acupoints” (which also have never been shown to exist and have no anatomic correlates). Basically, because acupressure is based on the same concepts from traditional Chinese medicine that acupuncture is, it’s just as much a load of prescientific mystical BS as acupuncture. It’s popular, though, probably because it promises the benefits of acupuncture without all those nasty needles. I know I’d rather just hold pressure on a couple of acupoints than have some guy (or woman) whose dedication to sterile technique is questionable stick several needles into my body.
In this case, Zick studies the effect of a self-administered acupressure technique for its effect on fatigue in breast cancer survivors. Fatigue, of course, can be a serious, debilitating problem during treatment for breast cancer (or any cancer). The disease, chemotherapy, radiation therapy, they all conspire to sap a patient’s energy, often leaving them feeling tired all the time. However, persistent fatigue can also be a problem after the successful treatment of breast cancer, and it’s unfortunately common. Zick et al note that approximately one-third of women experience moderate to severe persistent fatigue up to 10 years after the end of their treatment for breast cancer and then justify this study thusly:
Acupressure, a method derived from traditional Chinese medicine (TCM), is a treatment in which pressure is applied with fingers, thumbs, or a device to acupoints on the body. Acupressure has shown promise for treating fatigue in patients with cancer, and in a study of 43 cancer survivors with persistent fatigue, our group found that acupressure decreased fatigue by approximately 45% to 70%. Furthermore, acupressure points termed relaxing (for their use in TCM to treat insomnia) were significantly better at improving fatigue than another distinct set of acupressure points termed stimulating (used in TCM to increase energy). Despite such promise, only 5 small studies have examined the effect of acupressure for cancer fatigue.
One can’t help but wonder if acupressure is so promising if there have only been five small studies on it, but that’s just me channeling Mark Crislip. In any case, you can see where this is going. Zick et al decided to do a three-pronged single-blind randomized trial of:
- “Relaxing” acupressure
- “Stimulating” acupressure
- Usual care.
Now, before I tell you a single other thing about this study, I’m going to ask you to predict the outcome of this study. Go on. Think about it. Take as much time as you like. Try not to scroll down any further. Now, I was tempted to end the post here and then post the rest of my analysis tomorrow, but fortunately for you (and unfortunately for me) that’s not how I roll. So I’ll just have to trust you to have thought about it before making my prediction, and you’ll have to trust me that I made this prediction while reading the methods, all before I looked at a single result.
Think about it. You have usual care. That’s easy to predict. They won’t get better, or, if they do, they’ll only get slightly better. Then you have two forms of acupressure. It doesn’t really matter much in terms of my precition, but the specific points they used were:
Relaxing acupressure points consisted of yin tang, anmian, heart 7, spleen 6, and liver 3. Four acupoints were performed bilaterally, with yin tang done centrally. Stimulating acupressure points consisted of du 20, conception vessel 6, large intestine 4, stomach 36, spleen 6, and kidney 3. Points were administered bilaterally except for du 20 and conception vessel 6, which were done centrally (eFigure in Supplement 2). Women were told to perform acupressure once per day and to stimulate each point in a circular motion for 3 minutes.
So, you have a study with unblinded patients with a control group with no treatment other than usual plus two different acupressure treatments. Do you see where I’m going? Yes, my prediction was that there would be significant improvement in both acupressure groups and that there would be little or no improvement in the control group. I don’t even have to know what the outcome measures are to predict this, but for the sake of completeness, I’ll note that, to measure fatigue, the investigators used the Brief Fatigue Inventory (BFI), a scale that, according to the authors, correlates well with other fatigue measures.The instrument consists of 9 items, each measuring fatigue on a scale of 0 to 10, and the score is calculated from the mean of completed items. Scores of 4 or higher indicate clinically relevant fatigue. A 3-point change or a drop below 4 is considered a clinically meaningful change. Sleep quality was measured by an instrument called the PSQI, for which a score of 8 or higher suggests poor sleep quality and a 3-point change or a drop below 8 is considered clinically meaningful. Quality of life was measured by the LTQL, which is composed of 4 subscales, including somatic, spiritual and philosophical, fitness, and social support.
The rest of the design is as follows. 288 patients were randomized, with 270 receiving relaxing acupressure (n = 94), stimulating acupressure (n = 90), or usual care (n = 86). Women did acupressure for six weeks. One woman withdrew owing to bruising at the acupoints. Outcomes were assessed at 6 weeks and then, after acupressure was stopped, four weeks later at 10 weeks.
So what were the results with respect to fatigue? Here you go:
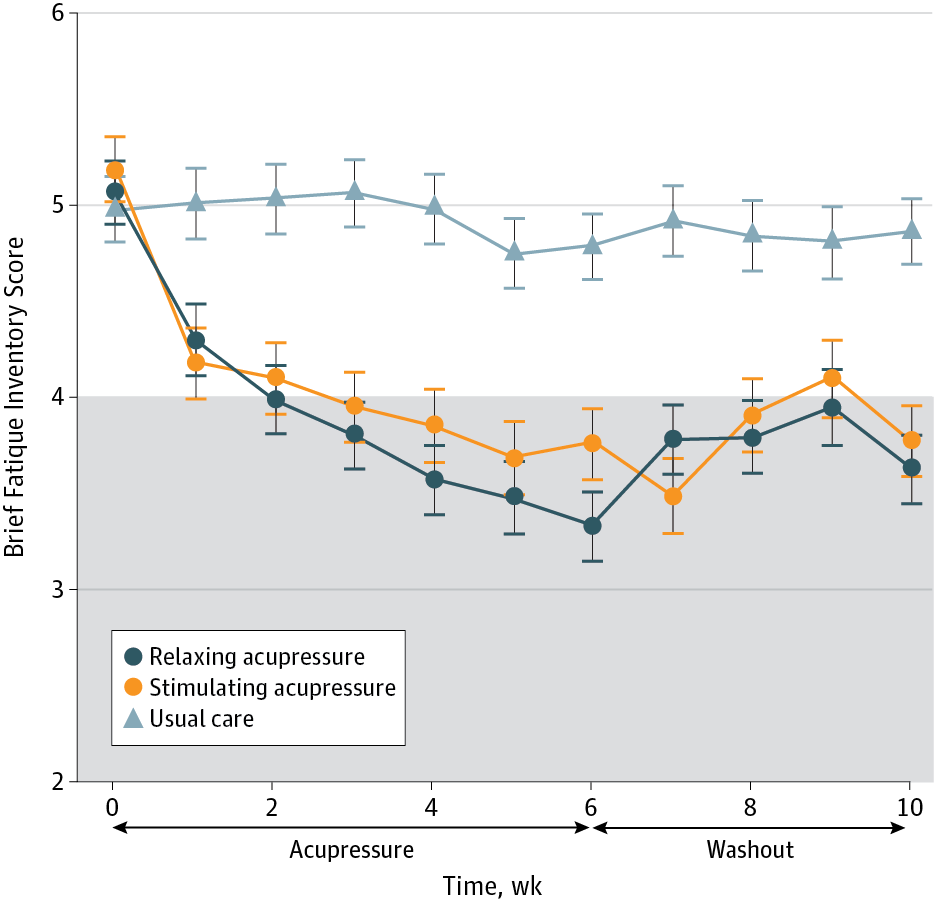
Yep, with respect to the primary outcome measure, fatigue, I appear to have corrected quite well. Both acupressure arms improved, but there was no difference between them, as I predicted.
What about the other outcome measures? The authors report:
At week 6, participants randomized to relaxing acupressure had significantly lower PSQI scores compared with usual care but were not significantly different from those randomized to stimulating acupressure. The stimulating acupressure arm was not significantly different from the usual care arm. There was no significant difference between the 3 study arms at week 10 (Table).
In other words, there was a small transient benefit to relaxing acupressure that didn’t last and could easily have been the result of placebo effects. So I was sort of wrong there, but not quite. Basically, for sleep, the results were worse than I predicted.
What about quality of life? The authors report:
Participants in the relaxing acupressure arm improved significantly compared with the usual care arm for 3 of the 4 quality-of-life subscales, including somatic, fitness, and social support at both 6 and 10 weeks. Stimulating acupressure was not significantly different from usual care for any subscale at either time point. There were no significant differences between the relaxing and stimulating acupressure arms for any subscale at either week 6 or 10.
What the authors fail to note is that these differences observed were quite small and that it could easily be questioned whether they were clinically significant.
What amused me in the discussion was how the authors tried to explain why both acupressure arms showed improvement in the BFI (fatigue). Basically, instead of accepting the the most obvious and likely explanation, they do a bit of woo handwaving:
Why might both acupressure arms significantly improve fatigue? In our group’s previous work, we had seen that cancer fatigue may arise through multiple distinct mechanisms.15 Similarly, it is also known in the acupuncture literature that true and sham acupuncture can improve symptoms equally, but they appear to work via different mechanisms. Therefore, relaxing acupressure and stimulating acupressure could elicit improvements in symptoms through distinct mechanisms, including both specific and nonspecific effects. These results are also consistent with TCM theory for these 2 acupoint formulas, whereby the relaxing acupressure acupoints were selected to treat insomnia by providing more restorative sleep and improving fatigue and the stimulating acupressure acupoints were chosen to improve daytime activity levels by targeting alertness.
Well, at least they got the nonspecific effects right. There is, however, nothing in this study that suggests any specific effects of acupressure on fatigue, sleep, or quality of life. This study is completely consistent with nonspecific effects.
So why did they choose such a poor control, usual care, that doesn’t account for placebo effects? Who knows? A far better design would have been to use a control akin to the ones used in acupuncture studies to produce a “sham acupressure” group. In acupuncture, the best placebo controls are either (1) retractable needles that don’t actually puncture the skin and whose tips are hidden so that the patient and acupuncturist can’t see where the needle meets skin or (2) using the “incorrect” acupuncture points. Now, #1 is not possible in acupressure, but #2 certainly is. Zick et al could have used “sham” acupressure in which the patients were taught to apply acupressure to the “wrong” acupuncture points. This control wasn’t used, hence the seemingly positive result.
This study is basically yet another example of a CAM study that fails to use the correct controls and therefore ends up with a result that seems positive but probably is not. Of course, we can’t know for sure because the correct control wasn’t used. Keeping an open mind demands that I at least consider the possibility that the improvement in, for instance, fatigue is greater than placebo, but we don’t know how much placebo effects there were. My suspicion is that both acupressure groups represent no more than placebo, but I could be rong. I doubt that I am, though. After all, in the absence of a plausible mechanism by which pressing special magic points on the body for a few minutes a day can alleviate serious fatigue, the prior plausibility for this study was very low, which means that the unimpressive results of this study are far more likely to be due to chance, placebo effects, and hidden biases in the study than they are to be due to a real, biological phenomenon.
Whenever I see a study like this coming from my alma mater, I can’t help but cringe. One wonders what the Bill Kelley of the late 1980s would think of the U. of M. Medical School of 2016 for cranking studies like this. I suspect he wouldn’t be pleased. Quackademia continues to expand.
Why is this study published in JAMA Oncology, and why are scientists allowed or encouraged to evaluate science by where you publish and by impact factor measurements?
My alt-med to English translation dictionary tells me that "has shown promise" means "has not been definitively debunked". Acupressure would be even harder to debunk than acupuncture: putting pressure on designated points is harder to fake than sticking needles in them. But that's the usual inversion of standard of proof we see from alt-med types. What we don't see is clear and convincing proof that their techniques work.
So going from 4.1 to 3.9 is a meaningful change, but going from 7.0 to 4.1 is not. The former could be discretization error. The latter is more likely to be a real change. If I were a smoker, I'd want some of whatever these authors are smoking.
Although it would probably be inappropriate, I would like to run a similar study where the control was "cuddling a teddy bear which had been infused with pheromones that were not detectable by normal means." The patients in the trial would be informed of this but not told that it was totally bogus. I'd be willing to bet that the control would perform as well or better than the acupressure treatments.
I'm embarrassed for them.
Why would JAMA Oncology publish this twaddle? It will, of course, be widely quoted as “proof” of the effectiveness of “woo”. A clearer example of Tooth Fairy Science would be hard to find.
Ms. Zick is a "Research Investigator". Non-tenured staff cannot publish unsuccessful trials, so she has to show an effect or her career ends at the same level of science as acupressure.
That isn't just an issue for staff. Many medical professors in the US have their academic year positions funded partially or entirely by grants and contracts (at most universities even fully "hard money" faculty are expected to cover their summer salary thus, or go unpaid). This system exists in other scientific fields as well, but not to the extent that it does in medical schools. Even if they are tenure track, they can still lose their jobs if they go too long without bringing in grant money.
It's true that funding agencies like to see positive results. This is a big reason why some researchers game the p < 0.05 threshold for significance. (I haven't read the paper in question, so I don't know if Zick et al. do this.) It's a particular problem with researchers and/or funding agencies that are motivated to see particular results (which is why scientists are expected to disclose financial COIs in their publications).
@ Mu
Rules are the same for "conventional" researchers. In the case of woo medicine, there is less harm, because we know that
it's bullshit. How long can we keep pretending that our academic system is compatible with science?
I think that acupressure is what my acupuncturist** did prior to the needling nonsense. Truthfully, when she poked at one place, I did feel something that felt better instantaneously but I've since discovered that if I aim well, I can easily achieve the same effect on myself. PLUS I don't have to play around with needles. fishbowls and liter jars.
Swimming in an idyllic pool, taking a plane and drinking wine accomplished more I think.
** recap: Someone-I-know funded a few sessions with a well-known TCM practitioner because of an injury I sustained as I won't pay for woo. Overall, I didn't feel much improvement that I could attribute to the treatments which concluded with 'cupping'- actually, 'concluding' isn't the right word as I QUIT right after.
If I had made a billion dolloars on quack supplements and wanted to fund an integrative medicine department somewhere, I'd tell U of M they can have it on the condition it's called the Gorski Center for Integrative Medicine just to drive a certain somebody nuts.
@Mark Thorson #10:
All Orac would have to do is take a photo of the Centre's nameplate and get it published somewhere where a person in the UK could see it. He would then be able to bring a libel action against the Centre in an English court...
Yeah, it is that f*cked (mostly).
Coming out of fatigue from chemotherapy would have been hard to measure in my case. Daily or even monthly changes are imperceptible to infinitesimal. It's only after years of hindsight that you notice an increase in strength and stamina at least in my case.
Since when does a sloppy study with a subject count of 43 get any attention at all. What happened to the minimum of 1000 subjects to say anything of statistical value. The bar set for this study was abysmal.
Sorry to hear about what's happening at U of M. That's really effed up. If I was a student there I would be outspoken and working to cut that crap out. Is there anything the Alumni can do?
The Brief Fatigue Inventory:
Because people chronic fatigue apparently has no effect on the ability of sufferers to stuff descriptions of the complexities of their everyday lives into an 11 pint Likert scale. No need to obscure the true survey subject, as any Psych 101 experiment would do. No need to actually observe them, or interview them so their responses could be discussed/unpacked/expanded.
Woo will indeed flourish as long as 'instruments' this simple-minded pass as 'science'.
______
Orac's commentary doesn't address the practical implications of the 'study', and the likely motivations for a medical institution to seek validation for this specific treatment: "Zick studies the effect of a self-administered acupressure technique". So, unlike most acu-studies, this one apparently wasn't set up to justify hiring quacks at UM. No, accupressure is DIY, and doesn't cost anything. "Take that, Big Pharma!," sez Big Insurance.
If Zick et. al. had used a control where the subjects were taught to apply acupressure to the “wrong” acupuncture points, they'd still just be assuming these fatigued patients could hit the prescribed points accurately/reliably. Unless, you know, they tattooed targets on the 'correct' spots for each group or something. :)
The way I was taught research methods (not in Med school, obviously), before you can make a causal inference, you have to control for other plausible explanations of the observed results. Doing that could actually yield an interesting study. E.g., the effect of calling the manipulation 'acupressure', invoking the whole qi mystique, vs. calling it something else with a non-woo explanation, or just non-explanation. Or having acupressure, sham acupressure, healing touch (no 'pressure'), sham healing touch, and pure reiki (no touch). Of course, since these 'modalities' would all be self-administered, the subjects in the non-accupressure groups would have to take classes in becoming reiki/HT 'masters'. Now wouldn't that be sweet, if the results showed the same effect of DIY woo for that, as for the results from 'professional' practitioners? There's a study for The Gorski Center for Integrative Medicine to commission for sure!
And someone will sponsor the Oracian Chair for Homeopathy
Mu,
I have a Nepal tenth rupee coin that I'll donate to this chair. The last I looked a Nepali rupee exchange rate is about 60 to a $, so a tenth rupee is about 1/600th of a dollar. Of course we are talking about homeopathy; so this would be considered a big donation.
That beats the 500 dong note I brought back from Vietnam. (I'd managed to spend the rest of what I had exchanged before leaving the country.) The current VND/USD exchange rate is over 22000, so that piece of paper is worth, appropriately, about $0.02. I saw 100 and 200 dong notes over there, but even at the time anything less than 1000 was uncommon, and the VND has lost about a third of its value against the USD since then.
[re-post after hitting the HWSNBN filter via cut-and-paste]
The Brief Fatigue Inventory:
Because people chronic fatigue apparently has no effect on the ability of sufferers to stuff descriptions of the complexities of their everyday lives into an 11 pint Likert scale. No need to obscure the true survey subject, as any Psych 101 experiment would do. No need to actually observe them, or interview them so their responses could be discussed/unpacked/expanded.
Woo will indeed flourish as long as 'instruments' this simple-minded pass as 'science'.
______
Orac's commentary doesn't address the practical implications of the 'study', and the likely motivations for a medical institution to seek validation for this specific treatment: "Zick studies the effect of a self-administered acupressure technique". So, unlike most acu-studies, this one apparently wasn't set up to justify hiring quacks at UM. No, accupressure is DIY, and doesn't cost anything. "Take that, Big Pharma!," sez Big Insurance.
If Zick et. al. had used a control where the subjects were taught to apply acupressure to the “wrong” acupuncture points, they'd still just be assuming these fatigued patients could hit the prescribed points accurately/reliably. Unless, you know, they tattooed targets on the 'correct' spots for each group or something. :)
The way I was taught research methods (not in Med school, obviously), before you can make a causal inference, you have to control for other plausible explanations of the observed results. Doing that could actually yield an interesting study. E.g., the effect of calling the manipulation 'acupressure', invoking the whole qi mystique, vs. calling it something else with a non-woo explanation, or just non-explanation. Or having acupressure, sham acupressure, healing touch (no 'pressure'), sham healing touch, and pure reiki (no touch). Of course, since these 'modalities' would all be self-administered, the subjects in the non-accupressure groups would have to take classes in becoming reiki/HT 'masters'. Now wouldn't that be sweet, if the results showed the same effect of DIY woo for that, as for the results from 'professional' practitioners? There's a study for The G0®$K! Center for Integrative Medicine to commission for sure!
Acupressure improves "social support". I wonder how it does that considering it's supposed to be redirecting qi or something.
Oh, wait. Having a nice acupressure researcher pay attention to you is "social support".
sadmar: There do exist reliable, validated, calibrated surveys to assess all kinds of things (diet, exercise, mental status, pain, ...). What I want to know is if any of the surveys described in this paper actually are validated survey tools, that are appropriate to the population in question.
Because a study is only as good as the methods used to measure outcomes, and if these are as bad as the fatigue one looks then this study is even more bogus than we thought.
A sham treatment group should always be included in these types of investigations. My sister's nursing unit is planning to do a essential oil aromatherapy trial and I asked her what the control group was. She said, "no treatment" group. I told her that she needed a sham aroma therapy group plus an "energizing" vs "calming" arms. The Sham treatment would be a commercial scent that has no purported aromatherapy value. After doing some research I found that it would be hard to find a sham treatment because any scent would be seen as having therapeutic value. Such is the non-specificity of these quack therapies.
I've had recent personal experience with the pain index, for reasons I won't get into here. It's a 0-10 scale whether you are in a hospital or a doctor's office. But realistically, if you are at 6 or 7 you should be heading for the emergency room, and if you are 8 or higher you should be going there in the back of an ambulance. There are good reasons for keeping the scale consistent, but you have to be aware that outside of a hospital setting only half the scale is realistically used.
The same thing applies for the fatigue index. We are told that at the beginning of the study everybody scores at least a 4 (as their fatigue would otherwise not be considered significant), and the figure shows the average is about 5 in all three study arms. But we don't see (at least not in the figure) what the upper end of the range is. From the size of the error bars, I'd guess that it tops out around 6, if that high. That's quite a bit of compression on what is nominally a ten-point scale.
Then there is the issue of variance. Depending on my state of mind, my pain index score could easily vary by a point or two, and I expect the fatigue index would have the same kind of issue. It's also well known that pain tolerance varies widely from one person to another, so what I'd consider a 3 might be a 1 for Alice or a 5 for Bob. Again, the fatigue index is likely to have a similar problem. You can mitigate these issues by taking a large enough sample size and having the people administering the tests be blinded. But an unscrupulous researcher could put a thumb on the scale (note: I have no evidence that Zick et al. did this). For instance, I would expect BFI scores to be higher if the background music during the test was, e.g., the Saturn movement of Holst's The Planets, than for, e.g., the Jupiter movement, because the former is intended to convey the effects of old age while the latter is more likely to inspire dancing. Likewise, fatigue varies with time of day; most people are more tired around 4 PM than around 10 AM (which is apparently why many departments schedule seminars and colloquia in the afternoon). Was there a systematic bias (conscious or otherwise) in scheduling the tests?
Eric @21: Exactly! That's a big part of validating a survey instrument, is describing *exactly* how it will be administered. How much training the interviewer (if used) has, the time of day, the type of room, all of that. Other wise, you're right, all those other variables will just tank it.
Perhaps this is perniciously off-topic, but Mr. Lund's comment got me wondering about departmental colloquia. In my experience, these are always in the late afternoon.
Because people are tired then? What I'm wondering: is this a good reason to have them in the late afternoon? Wouldn't it be more conducive to learning to have colloquia when people are less tired?
Carolyn, there are odors which are not essential oils that could be used as placebos. It just has to be non-toxic in low-dose exposure. Any solvent you'd find in a hardware store would qualify. Acetone might be too familiar to the subjects because it's used in nail polish remover. Lacquer thinner might be a good choice. If the nurses can order from a chemical distributor, ethyl acetate would be an excellent choice. It has a pleasant, non-solventy odor somewhat fruity because many ripe fruit emit it. If it was obtained in its pure synthetic form from a chemical distributor, nobody would claim it has healing properties.
And Carolyn, those nurses do have an institutional review board for experimentation on human subjects, right?
Eric Lund, #16:
There are a few people I know, men mostly, who would be delighted to expend 500 dongs.
(I can never resist a good straight line, or a good bi-line for that matter.)
More seriously, self-evaluation indices are full of pitfalls. The subject may rate some things differently if they feel they will be judged for it. Then there are other pitfalls. Vocabulary or understanding of terms used can vary, and questions may be answered before the question is fully understood.
The whole area of self-evaluation can produce results out of sync with reality. As an example the Levenson psychopathy index places me at about the 17th percentile for primary psychopathy, but at the 83rd for secondary psychopathy, which would come as a surprise to anyone who knows me well.
This "study" scored an unfortunately all-too-credulous couple of paragraphs in my local paper yesterday. *sigh*
Self-evaluation scales: there's an xkcd for that.
http://xkcd.com/883/
Dr(?) Lund,
I’ve had recent personal experience with the pain index, for reasons I won’t get into here. It’s a 0-10 scale whether you are in a hospital or a doctor’s office. But realistically, if you are at 6 or 7 you should be heading for the emergency room, and if you are 8 or higher you should be going there in the back of an ambulance. There are good reasons for keeping the scale consistent, but you have to be aware that outside of a hospital setting only half the scale is realistically used.
There's a lot of variability in pain perception, especially among the autistics clientele. Personnal experience in 2013 lead me to endure an inflamed appendix for at least 7 days and then one more day after it ruptured before calling an ambulance which lead me to spend 3 hours in the waiting area in a wheelchair before being seen by an ER physician, right around noon (I got in around 9am). I underwent surgery at midnight on that same day and they had to open me up, couldn't do it laparoscopically.
Alain
p.s. according to them, I was out of surgery by 5:30am.
Yah, apropos of the XKCD caption, after I wound up with a complex meniscus tear as a result of random street violence, I arbitrarily fixed "10" as "screaming." (They were trying to get me on crutches with a long brace; a short brace and a walker worked fine.)
The paramedic seemed surprised last week: "I think I know the answer to this question, but...."
"No, it's a baseline 8, but a 10 if I move the wrong way, and a 4 if I'm immobile in this exact sitting position."