
Matthew Yglesias writes regarding Moore's Law, which states that CPU transistor counts double every two years:
My pet notion is that improvements in computer power have been, in some sense, come along at an un-optimally rapid pace. To actually think up smart new ways to deploy new technology, then persuade some other people to listen to you, then implement the change, then have the competitive advantage this gives you play out in the form of increased market share takes time. The underlying technology is changing so rapidly that it may not be fully worthwhile to spend a lot of time thinking about optimizing the use of existing technology. And senior officials in large influential organizations may simply be uncomfortable with state of the art stuff. But the really big economic gains come not from the existence of new technologies but their actual use to accomplish something. So I conjecture that if after doubling, then doubling again, then doubling a third time the frontier starts advancing more slowly we might actually start to see more "real world" gains as people come up with better ideas for what to do with all this computing power.
The problem is that we know what to do with this power, we just need more of it. Actually, we don't even have enough power to handle the data we currently generate. Consider computation in genomics, something I've discussed before. Here's how Moore's Law holds up against DNA sequencing:
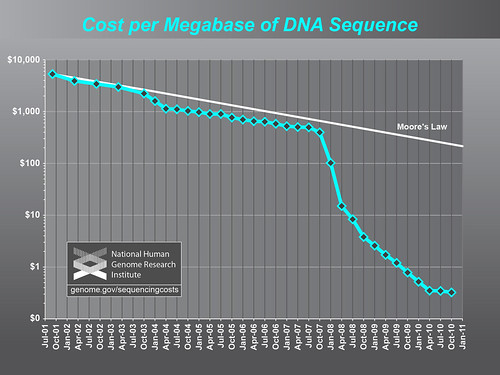
I think this figure is a little optimistic--I think you need more sequence than NHGRI claims, so multiply the cost three-fold. But that really doesn't change anything dramatically. And as I've noted before, this doesn't include all of the costs of sequencing (see here for what is and isn't included). And let's not even get started on read-write times to hard drives. We'll just pretend that magically happens.
By the way, physicists have it worse....
Anyway, the point is that we really do need more powerful computers regarding "their actual use to accomplish something." Slowing down would be a really bad thing.
Thank you for inf.
Physics is trivial compared to physiology.
There are what, a couple dozen fundamental particles? The wave functions are all linear combinations?
In physiology nothing is linear. The human genome is tens of thousands of genes and who knows how much DNA that is still mostly a complete mystery. A DNA sequence only gives you an amino acid sequence, it doesn't give you the protein shape, you have to fold it to get the shape and function.
When are we going to be able to model something with tens of thousands of non-linear and coupled parameters per cell?
The answer is never, unless Moore's Law extends for a few millennia.
The problem is AFAIK bigger in biology. Here's the process for genomic sequencing: 1) break sequence into small pieces, 2) generate sequence, 3) reassemble sequence, 4) annotate sequence, 5) compare to all existing genomic sequences.
#5, that one eats up computation, so much so that people usually pare it down to 5) compare it to one or two other genomic sequences.
@daedalus: The complications in physics are different from the complications in physiology, but physics can definitely benefit from the continuation of Moore's law. Unfortunately, physics simultaneously predicts a hard limit to Moore's law. You cannot make a transistor smaller than a single atom or molecule, no matter what you do.
Some of the issues in physics:
1. Many-body systems. Even a simple system like a three-body gravitational interaction cannot be solved analytically, nor can the Schrödinger equation for anything more complicated than a hydrogen atom. I know people who routinely run simulations involving millions of particles, and some simulations push that up to billions.
2. Nonlinearity. Yes, there is a lot of physics where you can't just construct every possible solution from a linear combination of other solutions. This crops up most often in areas like fluid mechanics; the Navier-Stokes equation is fundamentally nonlinear (and you can't linearize it without discarding a boundary condition).
3. Strongly interacting systems. Anybody doing QCD calculations has to deal with this problem.
4. Large data sets. Many particle physics experiments generate such a quantity of data (hundreds of terabytes per day without filtering) that most of it has to be discarded without a human ever looking at it. So the team tries to figure out how to tell the computer what constitutes an "interesting" event, at the risk of discarding some serendipitous discovery in the process.
Not that physiology isn't hard, but don't assume physics is easy.
throwing more hardware at a difficult problem is a brute-force, primitive sort of solution. it's necessary if the problem is genuinely, fundamentally difficult, such that no other solution but brute force exists --- and this may well be the case in genomics, i don't know enough about that problem space to tell.
but in the general case, problems tend not to be fundamentally hard, and it's often possible to get a much greater performance boost through algorithmic improvements than through buying more hardware. so while specific problem domains may need all the Moore's law improvements they can get --- climate research, possibly genomics, probably physics --- most problems could likely benefit more from better fundamental computer science efforts.
summary: i think Yglesias is correct in general, even if there will be notable specific exceptions to this rule.
Nomen its a lot easier (as biologists) to buy new hardware than it is to find some programmers who are able to cook up some new fancy pants algorithm.
Eric, I wasn't assuming physics was easy, just compared to physiology. I know that Moore's Law can't go on for millennia, and that even if it did, there are some problems that a brute force approach cannot solve.
I think it is the computer jocks who don't know what to do with the increases in hardware capabilities except to fill it up with bloat-ware. Sort of like Bill Gates once saying that "640K ought to be enough for anybody".
http://www.xkcd.com/793/
Just not a physicist this time. :)
(oh life; why do you have to emulate xkcd so closely?)
> When are we going to be able to model something with tens of thousands of non-linear and coupled parameters per cell?
I'm going to go with the following answer: the same time we can use pseudopotentials to accurately model a Pentium chip.
In an interview with Bob Cringely* for Triumph of the Nerds (PBS Documentary), Apple co-founder Steve Wozniak** said he personally was looking forward to the day that Moore's Law finally kicks in, because that will be the point where software finally learns it has to grow up because it can't rely on CPU speed improvements anymore.
Mind you, he said that sometime between 1992 and 1998, when the Pentium, the PowerPC and the Alpha, all were so fast already that it was evidence that the CPU was no longer the real bottleneck. Today, the bottleneck is actually getting data into the CPU and getting it out again - the bus, the disk drives, the memory, and today the network. I could (almost) watch a 1090p movie on a Pentium I 15 years ago, if it weren't for the slow bus, the slow video controller card, and the lack of a hard drive large enough to hold the dang thing.
Granted, that's watch a movie. Not process it. The issue with large-data apps is that it is actually too hard for HUMANS to actually determine what all that data actually means. So when this guy says he wants to slow Moore's law down, I wonder if he really is worried about speed or if he's just worried that he and people like him will be left behind by how much MORE information needs to be defined from the ever-increasing amount of data available.
*not the person who still uses that name at Infoworld
** I'm very impressed that Wozniak is in the Firefox built-in spell checker dictionary...and Infoworld isn't.
Mike, I don't understand how the graph supports your point. It shows the cost of sequencing declining, tracking Moore's Law until Oct. 2007, after which it falls even more rapidly, at least until near the end.
Nemo, that's the cost of sequencing per megabase sequenced. in essence, that's the cost of data generated dropping much faster than the cost of the hardware used to process the data, ergo, we're generating much more data than we get CPU to analyze it with --- dollar for dollar.
UNLESS someone can come up with some neato algorithmic improvement to speed up the genomics data analysis without needing to throw more CPU at it, brute-force style. but depending on just what that data analysis entails, such cleverness may not be possible. if the problem is NP-complete, for instance, the genomicists are stuck buying more CPU and that's that --- i honestly don't know if that's so or not.
Moore's Law was originally based on the observed the reduction in the cost of computing power (such as processing speed or memory), but it actually applies to a wide range of other technologies. Interestingly, the time span for a 50% drop in computing power, about 1.8 to 2 years, is almost the same as the decline in the costs of DNA sequencing (per finished base pair) over the last 20 years, although there has been a further marked reduction in DNA sequencing costs in the last couple of years as noted in your figure. Also during the last two decades, the size of the Internet has been doubling every 5.3 years and the amount of data transmitted over the web on average has doubled each year.
It is likely that the steady and dramatic improvements in diverse technologies, and with this world knowledge, has arisen from the synergies provided by the intersections of these technologies. For example, advances in DNA sequencing would not have been feasible without improvements in computing power. It also appears that recent improvements in proteomics, for example with mass spectrometry or production of specific antibodies, would not have been possible without gene sequence data.
The real problem arises when some areas of science and technology become underfunded or relatively neglected relative to other, more outwardly sexier endeavors that suck up the lion's share of support. I find it intriguing that in the biomedical field, in the US and Canada, there is an over-emphasis on developing genomic approaches and solutions. By contrast, in Europe, there appears to be a much stronger tradition for the study of proteins and small molecules.
In the ultimate search for solutions and understanding, under-explored areas of scientific enquiry could become the bottlenecks that severely compromise realization of the true value of the public investment in science and engineering. For example, the actual rate of improvements in the diagnosis and treatment of most diseases is still pathetically slow over the last few decades. It would be more prudent to take a more balanced approach in the funding of scientific research if the ultimate goal is real improvements in the health and welfare of humans and the other species on this planet.