
Note that I said cranky, not mad. Mad is reserved for moral degenerates who cut funding to assist people with cerebral palsy. But cranky? Yes. Recently, I've come across a couple of papers that describe interesting collections of E. coli. For example, one paper isolated a bunch of E. coli from soil and water in Hawaii to determine if there is a dominant point source of fecal contamination and if there are sustainable populations of E. coli in Hawaiian soils (which would mean we can't use simple counts of E. coli to determine if a water source is contaminated by feces). Another paper isolated E. coli from a Californian river system to determine if these isolates were primarily of human or animal origin. As studies go, they're fine.
Except for one thing: how they genetically characterized the E. coli. One study used rep-PCR, the other pulsed field gel electrophoresis. You basically end up running pieces of DNA through an agarose gel, and end up with something that looks like this:
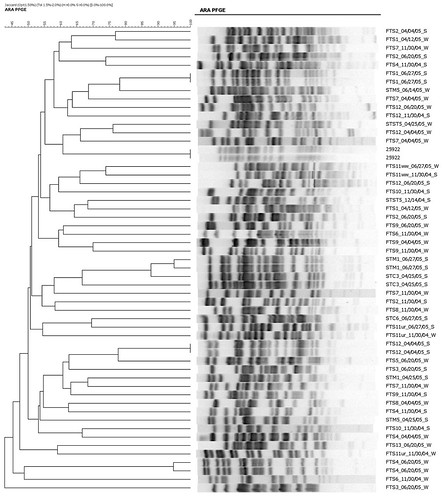
Depending on how thick the gel is, how strong the illuminator is your using to backlight the gel, how much DNA is used (not to mention with rep-PCR, all the potential PCR replication issues), you can get different banding patterns with the same strain.
But that's not what makes me cranky.
What makes me cranky is that these methods aren't very 'portable.' It's really hard to compare them between labs (and, for rep-PCR even different PCR machines in the same lab). PFGE can also have significant lab-to-lab variation. State public health labs and CDC, which inexplicably still use PFGE for outbreak surveillance, spend a lot of time ensuring quality control--it's not a trivial issue.
In other words, I have no idea what the genotypes of these E. coli are except within the context of study. Contrast this with a sequenced-based method such as multilocus sequence typing ('MLST') where short segments of multiple genes are sequenced. Not only are these data portable, in that a sequence in one lab can be readily compared to a sequence generated in another lab, but MLST is independent of sequencing technology. For instance, when I determined that the German outbreak E. coli HUSEC041 was actually closely related to a strain of E. coli we had seen a decade earlier*, I used the sequence data generated by BGI and compared to sequence in a database that had been generated years earlier by a completely different technology.
Between the two studies I mentioned--and, again, they're not bad in terms of the science--there are over 1,800 E. coli isolates in those two papers alone (and the field of water management generates many thousands of such isolates every year). Wouldn't it be nice to know if any of them are related to HUSEC041? Or O157:H7? Or some other E. coli of interest? I think so, but I'm just a Mad Biologist....
Now, there are two points against MLST that can be made. First, is that MLST doesn't always have the resolution that PFGE does. After, if a strain acquires a plasmid or a phage, the size of the chromosomal pieces will change (PFGE chops up the genome by using enzymes that cut the genome in specific places). I would argue that if you want that level of fine scale resolution, MLST combined with a really rapidly evolving target like hypervariable tandem repeat loci is the way to go (rep-PCR, on the other hand, doesn't evolve that quickly, so it's not really an improvement to begin with).
The other issue is cost. I would argue this is overblown: even if you pay a private company to do the sequencing, the total cost runs to about $90 per isolate (and that's retail--bulk customers usually get discounts these days). But as I've discussed regarding sequencing technologies, there's a difference between price and cost: the real cost of running PFGE on a bunch of strains is pretty close to MLST once labor costs and throughput times are considered.
All these strains and no idea what they are.
We are very cranky.
*From what I've been able to gather from multiple sources, the Karch laboratory at the University of Munster had this information a week before I 'discovered' it, but public health authorities went with the killer bacterium version. That was incompetence bordering on the criminal. On the other hand, it does demonstrate the power of simple sequence as a corrective to official idiocy.
Excellent piece! I am also shocked/dismayed/mightily annoyed when people use non-sequence based methods of typing.
Some of this may be data that was generated, or started, before sequencing prices dropped...also in regard to the first 'limitation', that is also a strength of MLST - acquiring a phage or movement of transposons may be meaningless if you are interested in evolutionary relationships or fine-scale mapping of isolates.
But yes, sequencing is the way to go.
I hear you. That's why I like spa typing in Staph--only one gene, and generally correlates well with MLST. (Of course, horizontal transfer can occur so that can make it problematic, but probably less so in Staph than E. coli).
For us, because we have more students than technicians at this point, PFGE is cheaper than MLST (ours works out to closer to $105/isolate for the latter), so usually we do PFGE or spa typing first, and then MLST on a handful of isolates identical by those means for confirmation. That way we keep costs low and still have portable/repeatable information.
Well, what if you're not interested in evolutionary relationships but in identifying the source of an outbreak? Public health officials are understandably more immediately concerned with identifying and eliminating the source of an outbreak than the phylogeny.
The problem is, that's short-sighted. It can show you how to potentially ID/eliminate it for that outbreak, but what about the next 20 outbreaks from this strain? By doing typing that's more portable, you can get a better handle on the overall epidemiology/ecology of that strain, and in doing so even prevent future outbreaks.
I remember asking the senior author when the Hawaii paper came out in press to find more about phylogroups and basic stuff on the strains. I didn't really get a clear answer.
This is potentially a very nice population to study, if exploited correctly. I don't fully adhere to the critics as these strains are not pathogenic but more looked at in an ecological context (most pathogenic strains are "properly typed") so the argument of having the info in case an outbreak occurs is not valid.
Overall diversity (as shown by rep-PCR with all its limitations) is an important thing to look, especially in nonhost environments. Nevertheless, this doesn't provide a lot of info compared to MLST so that's a bit too frustrating. You could argue that MLST is expensive for a small ecology lab, especially if you wish to look at large collections of strains (I know this too well), but in the case of E. coli, there are cheap ways to do something approximate and more informative than rep-PCR...
Knowledge of the evolution of the strain may indeed be extremely useful, but it does not necessarily identify the specific process control deficiencies or failures at the operational level that result in proliferation and exposure. Correctly identifying those deficiencies should result in developing more robust processes that will prevent future illnesses, not only outbreaks and not only from this specific strain or this specific source. In my view, different typing methods are complementary and appropriate for studies at different scales with different objectives.