
Sometimes when you go digging through the databases, you find unexpected things.
When I was researching the previous posts on insulin structure and insulin evolution, I found something curious indeed.
 Human insulin, colored by rainbow. Image from the Molecule World iPad app by Digital World Biology.
Human insulin, colored by rainbow. Image from the Molecule World iPad app by Digital World Biology.
I wanted to find out how many different organisms made insulin, so I used a database at the NCBI called Blink. Blink is a database of protein blast search results. Using Blink can save you lots of time because it organizes blast results from all the organisms in the non-redundant protein sequence database, but getting to Blink can be tricky because it's a little hard to find.
I got to the Blink results by finding the human insulin preproprotein sequence (NP_001278826), then I clicked the Blink link on the side of the page to get all the Blink results for human insulin.
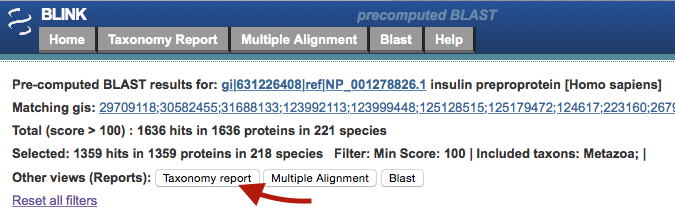
If I used the Taxonomy report link, I would see a list summarizing all 218 species with proteins similar to insulin.
Matching sequences are also organized into larger groups. As you can see below there were 1359 results from animals with mouths (metazoans), some results classified as "Other" (those came from protein structures), and curiously one result identified as "Plant."
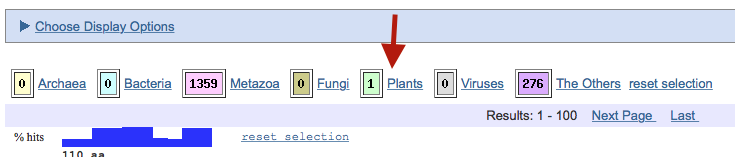
Now, I know that people have put insulin genes into plants as a way of producing this drug, but I hadn't read anything about plants making insulin before.
What else could I do? I had to click the link and see where it led.
I chose "Only plants."
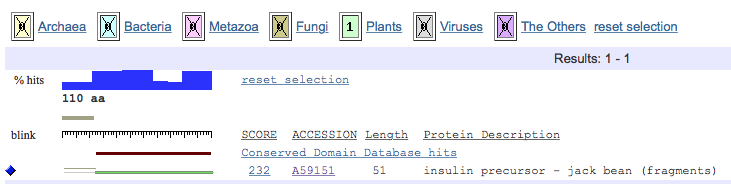
Then, I clicked the blast score (232) to see how well the human preproinsulin matched the plant protein.
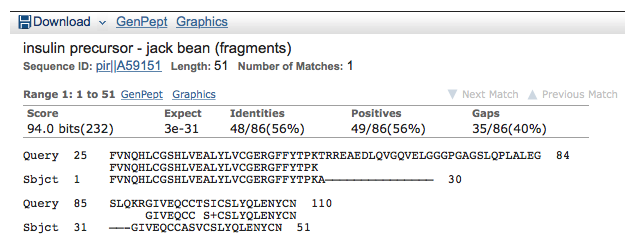
The alignment looked good, you can see in the image above that over half the amino acids are identical and the E value, at 3 x 10-31 shows me there's very little chance of getting a match this good from random sequences. The middle protein is missing from the plant sequence, but that's the part that gets cut out during processing so that's okay.
Still...
These results bothered me.
Over 202 plant genomes have been sequenced and are in the NCBI database. Why was there only one result from a plant? That seemed strange. If plants really make insulin, there should be more results from plant sequences.
So, I clicked the accession number (PIR A59151) to learn more about this protein sequence from jack beans and where it came from.
Clue 2: The next clue to a possible problem came from the title of the paper:
"Jack bean seed coat contains a protein with complete sequence homology to bovine insulin."
Not only was this sequence the only sequence from any plant that matched insulin, it was supposedly identical to insulin from a cow!
I decided to look for the paper. And I found that this group had published a second paper in 2003, with this title:
"A protein with amino acid sequence homology to bovine insulin is present in the legume Vigna unguiculata (cowpea)."
Clue 3: Not only was this group the only lab to ever find a plant insulin protein, the protein they sequenced was identical to cow insulin, and they found it twice.
Interesting coincidence.
As I skimmed through the papers, I learned that this group obtained the sequence of these proteins by protein sequencing, and they were using bovine insulin in the lab for other experiments.
This sounded fishy.
Clue 4: To be complete, I also used tblastn to translate the DNA from all 202 plant genomes and compare the predicted protein sequences to the insulin protein sequence. Suffice it to say, none of the 202 plant genomes contained genes for bovine insulin.
It seems pretty clear that the jack bean protein insulin sequence was obtained from a bit of contaminating cow protein.
Why is this sequence in the NCBI database if it's misidentified?
The presence of the cow insulin sequence from jack beans illustrates an important point about the NCBI database. It's an archive. Sequences get entered that aren't always right and they can persist.
The take home message is this: when a result seems unlikely, it probably is.
Be sure to look for other lines of evidence before deciding a result is correct.
It seems to me that sequences like this should have some kind of red flag or notation to indicate a potential problem. Until that time, examples like these can be good case studies for biology students.
Images: The image of human insulin was made with Molecule World, an iPad app from Digital World Biology.
References:
1. Oliveira,A.E.A., Machado,O.L.T., Gomes,V.M., Xavier-Neto,J., Pereira,A.C.P., Vieira,J.G.H., Fernandes, K.V.S. and Xavier-Filho,J. "Jack bean seed coat contains a protein with complete sequence homology to bovine insulin." Protein Pept. Lett. 6, 15-21 (1999).
2. Venancio, T.M., Oliveira,A.E.A., Silva, L.B., Machado,O.L.T., Fernandes, K.V.S. and Xavier-Filho,J. "A protein with amino acid sequence homology to bovine insulin is present in the legume Vigna unguiculata (cowpea)." Brazilian Journal of Medical and Biological Research (2003) 36: 1167-1173.
Inaccurate data in NCBI? That's unpossible!
In reality, NCBI is overwhelmed with the data. They have a mandate to store (and process) all the data from NIH but they have little say in the way data is delivered. So they routinely get bits and pieces of lab technicians along with the sequenced DNA of new and exciting species. They try to filter out such contaminations, but it's not always successful.
Great find! A normal BLASTP search does not find it because the default thresholds are too high. Checking if a distinctly Animalia protein can be found in other kingdoms might be a good way for curators to discover and fix mistakes in the database. If you open up the Insulin precursor in Jack Beans protein description NCBI page it says the sequence was first entered in Dec 1999. I highly suspect contamination as well but someone needs to repeat the experiment with modern equipment to confirm it is wrong before it is vaped.
@Shadow Caster: I disagree. Repeating the experiment wouldn't provide any useful information. If, as I suspect, they tried to isolate an insulin protein from jack bean, in a clean environment, they would get a negative result.
The best test is to see if related plants (or this plant) have a gene that would code for this protein. And, as I found, they do not.
So, it's pretty clear this is a protein sequence from a contaminant.