
I have not updated my model for predicting primary outcomes in the Democratic contest, but since the last few predictions were very accurate, I don't feel the need to do so. However, I will before the California primary, just in case.
Meanwhile, my model suggests the following for today's primaries.
Kentucky should be nearly a tie, though my model suggests that Sanders will get one more delegate than Clinton (Clinton: 27, Sanders: 28).
The model also suggests that Sanders will win in Oregon, Clinton: 24 and Sanders: 37.
There is very little polling in Kentucky, but the latest poll from early March has Clinton slightly ahead. I expect that to be wrong.
Kentucky will be interesting. Clinton has been campaigning fairly strongly there, with TV ads and a lot of hand shaking. Sanders has been campaigning very little there lately, but he was campaigning heavily up until just a couple of days ago.
In Oregon, there is also very little in the way of polls, but the one poll I've seen, from just a week ago, has Clinton winning handily.
You will remember that my model is based mainly on ethnicity, and Oregon is a white state, thus the predicted Sanders win. But Oregon is also way different than other states. Politically it is more liberal, and they vote by mail. Every resident of the state is automatically registered. So, Oregon may be the best state in the US to represent a truly democratic and open process. Some say this arrangement favors Sanders, but in fact, it seems to favor neither candidate. So, Oregon will be interesting.
Results will be posted here when they are available. The Oregon results will not be available until really late, maybe Wednesday some time.
RESULTS
With 99.8% of the vote counted, Hillary Clinton is being called the winner of the Kentucky Primary, but about 1,800 votes.

Meanwhile, in Oregon ...
My model, which is generally pretty accurate, predicted a Sanders win, and that happened.
But Sanders did not do as well as he should have. Here's the numbers with about 77% counted.
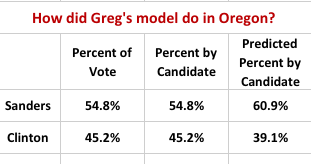
This may change as more votes are counted. And, the numbers are not really all that far off. But, Sanders, in the end, will take fewer delegates from Oregon to the national convention than I was thinking he would, and he needed more than I was thinking to have any kind of chance of closing the gap.
It will be interesting to see if, when I re-run the model with the latest info, the Oregon gap between expected and actual closes up. (Since the Oregon data will be in the model, it will close up, but by how much?)
Oregon might have some explaining to do, and that will probably be in the framework of their new and unique way of voting. This could be quite interesting.
'Every resident of the state is automatically registered'
Not quite correct. Motor voter. You're registered when you go in to the dmv for a license, idea, or learners permit. If you don't go into the dmv you have to register yourself.
Oops, I.D. not idea
Once again, you're correct; a near tie in Kentucky, a decent win for Sanders in Oregon.
I'm puzzled why your model, purportedly based on demographics, shows Sanders winning in California, which is a minority majority state. Sure, independents can participate in the Democratic primary, and the black population approximates the national average, but Clinton has so far done well with Latinos, and the jungle primary is expected to advance two women, both Democrats, neither necessarily white, to the general election to replace Barbara Boxer.
(Apropos of nothing: I've voted for Harris, of course, and will again. I've contributed to Sanchez, and received as a consequence a couple of mildly risqué Christmas cards.)
Jim, the best single predictor across the US has been percentage of African American voters. The percentage of African American voters in California is quite low.
When I've run the model with all the ethnic data in place, the analysis tells me that all the variables but AA voters introduce noise. In other words, using only AA voters, I get the highest R-squared value.
But, California has a lot of Latino voters, and that increases the diversity and may have a big impact there. So, when I rerun the model with all the updated data, I'll put all the variables back in and see if California changes.