
As you know, I’ve been running a model to predict the outcomes of upcoming Democratic Primary contests. The model has change over time, as described below, but has always been pretty accurate. Here, I present the final, last, ultimate version of the model, covering the final contests coming up in June.
Why predict primaries and caucuses?
Predicting primaries and caucuses is annoying to some people. Why not just let people vote? Polls predict primaries and caucuses, and people get annoyed at polls.
But there are good reasons to make these predictions. Campaign managers might want to have some idea of what to expect, in order to better deploy resources, or to control expectations. But why would a voter who is not involved in a campaign care?
I had a very particular reason for working on this project, of predicting primaries and, ultimately, the course of the Democratic race for the Democratic nomination as a whole. When this campaign started, there were several candidates, and they all had positive and negative features. Very early in the process, all but two candidates dropped out, and I found myself liking both of them, though for different reason. I would have been happy supporting either Hillary Clinton or Bernie Sanders.
Personally I believe that it is good to vote, during a primary, for the person you like best in direct comparison among the other candidates. But at some point, it may be wise to support the one you feel is most likely to win. There are two closely related reasons to do this, and I think most observers of the current campaign can easily understand them. One is to help build momentum for the candidate that is going to win anyway. The other is to limit the damage that is inevitable during a primary campaign as the candidates fight it out.
So, early on in the process, I decided to see if I could produce a reliable method to predict the final outcome of the primary process, in order to know if and when I should get behind one of the candidates. That is the main reason I did this. In order for this method to meet this and other goals, it had to be more accurate than polls.
There are other reasons. One is that it is fun. I’ve been doing this in primaries and general election campaigns for quite a few elections. I like data, I like analyzing data, I like politics, I like trying to understand what is going on in a given political scenario. So, obviously, I’m going to do this.
Another reason is to test the idea that the voters are changing their minds over time. In order to do this one might use all the primaries and caucuses to date to predict future primaries and caucuses, and then, if the predictions go out of whack, you can probably figure that something new is going on. This relates to overall feelings among the electorate as sampled by each state, but it also relates specifically to ideas about why a particular state reacted to the campaigns the way it did.
An example of this came up recently when Bernie Sanders won in West Virginia. My model had predicted a Sanders win there, and the actual vote count was very close to the prediction. Since that prediction was based on voter behavior across the country to date, I was confident that nothing unusual happened in West Virginia. But, something unusual should have happened there, according to some conceptions of this campaign.
The economy of West Virginia is based largely on coal mining, and there are lot of Democrats there. (Democrats in local elections; they tend to vote for Republicans in the general.) So, it was thought that the voters would pick a candidate based on a perceived position on climate change and coal. Clinton went so far as to pander to the West Virginians with a rather mealy mouthed comment about how we could still keep mining coal as long as we figured out a way to have it not harm the environment. That was the Clinton campaign doing something about the coal mining vote. Others thought that a Sanders win there would indicate that he somehow managed to get a strong climate change message across to coal miners. That idea is a bit weak because when it comes down to it, Clinton and Sanders are not different enough on climate change to be distinguished by most voters, let alone coal supporting voters. In any event, the win there by Sanders was touted as a special case of a certain candidate bringing a certain message to certain voters. But, he then lost in the next coal mining state over, Kentucky, and in both states the percentage of voters that picked Clinton and Sanders was almost exactly what my model predicted, and that model was not based on climate change, coal, or perceptions or strategies related to these things, but rather, on what voters had been doing all along.
So, nothing interesting actually happened in West Virginia. Or, two interesting things happened that cancelled each other out perfectly. Which is not likely.
In short, the closeness of my model to actual results, and the lack of significant outliers in the overall pattern (see below), seems to indicate that the voters have been behaving the same way during the entire primary season, by and large. This is a bit surprising when considered in light of the assumption that Sanders would take some time to get his message across, and pick up steam (or, I suppose, drive people over to Clinton) over time. That did not happen. Democratic voters became aware of Sanders and what he represents right away, and probably already had a sense of Clinton, and that has not changed measurably since Iowa.
How does this model work?
For the first few weeks of this campaign I used one model, then switched to an entirely different one. Then I stuck with the second model until now, but with a major refinement that I introduce today. The reason for using different models has to do with the availability of data.
All the models use the same basic assumption. Simply put, what happened will continue to happen. This is why I sometimes refer to this approach a a “status quo model.” I don’t use polling data at all, but rather, I assume that whatever voters were doing in states already done, their compatriots will do in states not yet done. But, I also break the voters down into major ethnic groups based on census data. So, for each state, I have data dividing the voting populous into White, Black, Hispanic and Asian. These racial categories are, of course, bogus in many ways (click on the “race and racism” category in the sidebar if you want to explore that). But as far as American voters go, these categories tend to be meaningful.
The fist version of the model used exit polling (ok, so I did use that kind of polling for a while) to estimate the percentage of black voters who would prefer Sanders vs. Clinton. I used the simple fact that in non-favorite son states that were nearly all white Clinton and Sanders essentially tied to estimate the ratio of preferences for white votes at about even. I ignored Hispanic and Asian voters because the data were unavailable or unclear.
This model simply simulated voters’ behavior (in the simplest way, no randomization or multiple iterations or anything like that). I also used some guesses (sort of based on data) of the ethnic mix for Democrats specifically in so doing. That somewhat clumsy model worked well for the first several primaries, but then, after Super Tuesday there were (sort of) enough data points to use a different, superior method.
This method simply regressed the outcome of the primary (in terms of one candidate’s percentage of the vote) against the available ethnic variables by state. Early on, the percentage of Hispanic or Asian did not factor in as meaningful at all, and White and Black together or White on its own did not work too well. What gave the best results was simply the precent of African Americans per state.
“Best results,” by the way, is simply measured as the r-squared value of the regression analysis, which can be thought of as the percentage of variation (in voting) explained by variation in the independent variable(s) of ethnicity.
Primaries vs. Caucuses and Open vs. Closed
Many things have been said about how each of the two candidates do in various kinds of contests. We heard many say that Sanders does better in Caucuses, or that Clinton does better in closed primaries. During the middle of the primary season, I tested that idea and found it wanting. Yes, Sanders does well in caucuses, but the ethnic model predicts Sanders’ performance much better than the caucus-no caucus difference. It turns out that caucusing is a white people thing. There are no high diversity states where caucusing happens. It is not the caucus, but rather the Caucasian, that gives Sanders the edge.
This graph shows how Sanders vs. Clinton over-performed in caucuses vs. primaries.
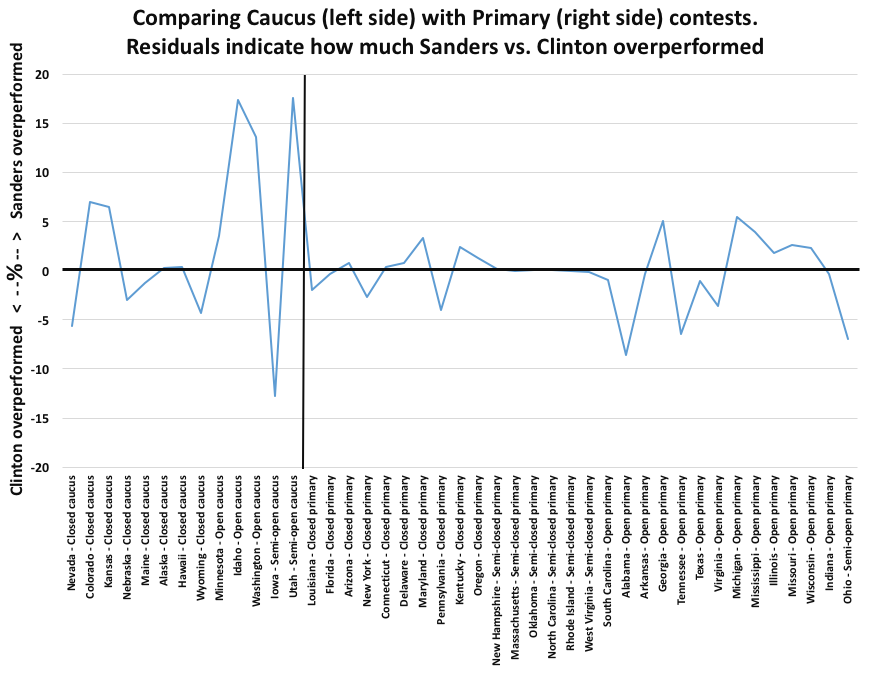
The value plotted is the residual of each contest in relation to the model, or how far off a theoretical straight line approximating the pattern of results each contest was. Two things are apparent. One is that caucuses are less predictable than primaries. The other is that while Sanders did over-perform in several caucuses, this was not a fixed pattern.
This graph shows the residuals divided on the basis of whether the contest was open (so people could switch parties, or engage as an independent) vs closed (more restricted).
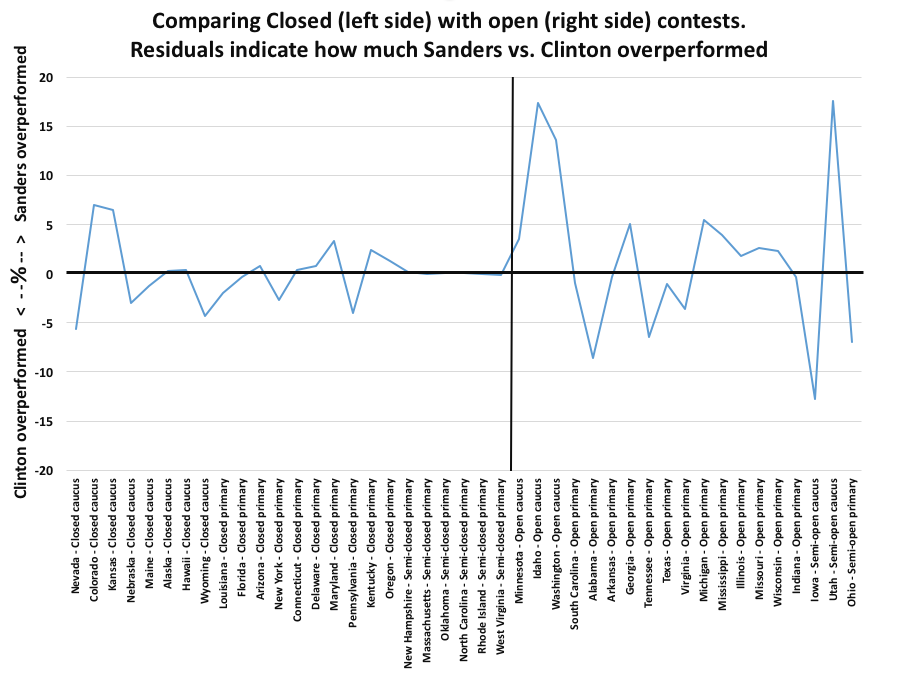
Open contests were more variable than closed contests, but it is not clear that either candidate did generally better in one or the other.
After many primaries and caucuses were finished, there became enough data to use the kind of contest as a factor in conducting the regression analysis. There are a lot of ways to do this, but I chose the simplified brute force method because it actually gives cleaner, and more understandable, results.
I simply divided the sample into the kind of contest, and then ran a multivariable regression analysis with each group, with the percent of Sanders plus Clinton votes cast for Clinton as the dependent variable, and the percentage of each of the four ethnic categories as the independent variables. There are some combinations of caucus-primary and open-closed/semi-open/semi-closed that are too infrequent to allow this. For those contests, I simply developed a regression model based on all the data to use to make a prediction in each of those states. The results, shown below, use this method of developing the most accurate possible model.
How does this sort of model actually make a prediction?
The actual method is simple, and most of you either know this or don’t care, but for those who would like a refresher or do care…
The regression model, using multiple variables, produces a series of coefficients and an intercept. You will remember from High School algebra that the formula for a line is
Y = mX + b
X is the independent variable, along the x axis, and Y is what you are trying to predict. m is the slope of the line (a higher positive number is a steeply upward sloping line, for example) and b is the point where the line crosses the Y axis.
For multiple variables, the formula looks like this:
Y = m1(X1) + m2(X2) + … mn(Xn) + b
Here, each coefficient (m1, m2, up to mn) is a different number that you multiply by each corresponding variable (percent White, Black, etc.) and then you add on the intercept value (b). So, the regression gives the “m’s” and the ethnic data gives the “X’s” and you don’t forget the “b” and you can calculate Y (percent of voters casting a vote for Clinton) for any given state.
So, enough already, who is going to win what primary when?
Not so fast, I have more to say about my wonderful model.
How have the public opinion polls done in predicting the contests?
Everybody hates polls, but like train wrecks, you can’t look away from them.
Actually, I love polls, because they are data, and they are data about what people are thinking. The idea that polls are inaccurate, misleading, or otherwise bogus is an unsubstantiated and generally false meme. Naturally, there are bad polls, biased polls, and so on, but for the most part polls are carried out by professionals who know what they are doing, and I promise that those professionals are aware of the things you feel make polls wrong, such as the shift from landlines to cell phones.
Anyway, polls can be expected to be reasonable predictors of election outcomes, but just how good are they?
Looking at a number of races today, excluding only a few because there were no polls, I got the Real Clear Politics web site averages for polls across the states, transformed those numbers to get a percentage of the Sanders + Clinton vote that went to Clinton, and plotted that with the similarly transformed data from the actual primaries and caucuses. The r-squared value is 0.52443, which is not terrible, and the graphic shows that there is a clear correlation between the two numbers, though the spread is rather messy.
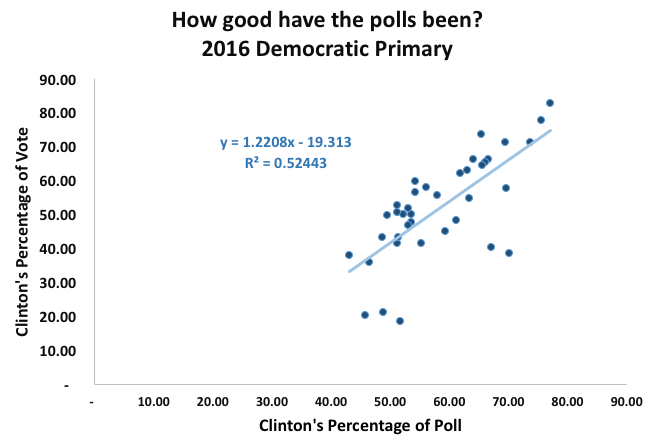
The ethnic status quo model outperformed polls
My model is actually many models, as mentioned. I have a separate regression model for each of several kinds of primary, including Closed Caucuses, Closed Primaries, Semi-Closed Primaries, and Open primaries. I did not create separate models for the much rarer Semi-Open Primary, Semi-Open Caucus or Open Caucus style contests, as each of these categories had only one or a few states. Rather, the model used to calculate values for these states is derived from all the data, so addressing specific quirkiness of each kind of contest is sacrificed for large sample size.
I also generated models that included White, Black, Hispanic, and Asian; each of these separately; and various combinations of them. As noted above, the best single predictor was Black. Hispanic and Asian were very poor predictors. White was OK but not as good as Black. But, combining all the variables worked best. That is not what usually happens when throwing together variables. It is more like mixing water colors, you end up with muddy grayish brown most of the time. But this worked because, I think, diversity matters but in different ways when it comes in different flavors.
When the total data set was analyzed with the all-ethnicity model, that worked well. But when the major categories of contest type was analyzed with the all-ethnicity model, some of the data really popped, producing some very nice r-squared values. Closed caucuses can not be predicted well at all (r-squared = 0.2577) while Open Caucuses perform very well (over 0.90, but there are only a few). The most helpful and useful results, though, were for the closed primary, open primary, and Semi=closed primary, which had R-squared values of 0.69, 0.61, and 0.74, respectively.
What this means is that the percentage of the major ethnic groups across states, which varies, explains between about 61 and 74% of the variation in what percentage of voters or caucusers chose Clinton vs. Sanders.
Polls did not do as well, “explaining” only about half the variation.
So, the following graph is based on all that. This is a composite of the several different models (same basic model recalculate separately for some of the major categories of contest), using nominal ethnic categories. The model retrodicts, in this case, the percentage of the vote that would be given to Clinton across races. Notice that this works very well. The few outliers both above and below the line are mainly caucuses, but the are also mainly smaller states, which may be a factor.
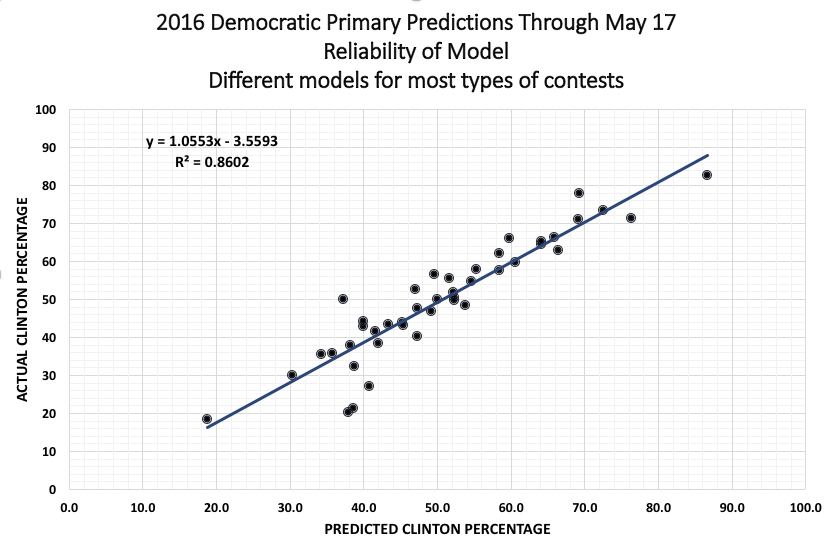
Who will win the California, New Jersey, Montana, New Mexico, North Dakota, South Dakota, and D.C. primaries?
Clinton will win the California, New Jersey, New Mexico and D.C. Primaries. Sanders will win the Montana, North Dakota, and South Dakota primaries. According to this model.
The distribution of votes and delegates will be as shown here:
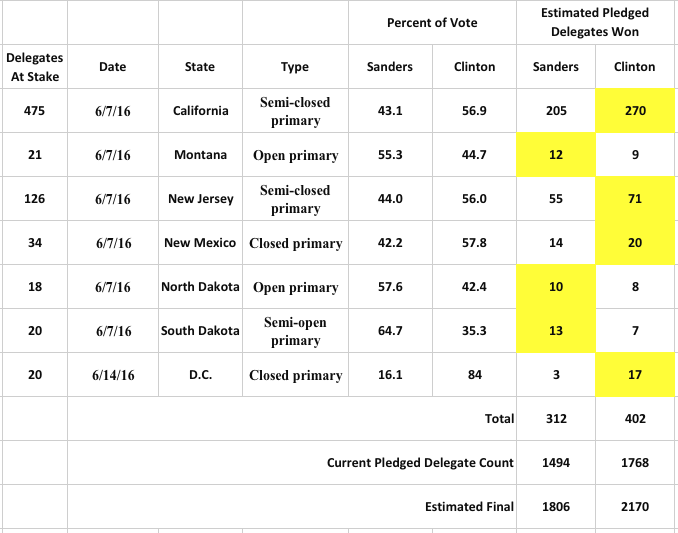
This will leave Sanders 576 pledged delegates short of a lock on the convention, and Clinton 212 pledged delegates short of a lock on the convention. If Super Delegates do what Sanders has asked them to do, to respect the will of the voters in their own states, then the final count will be Sanders with 2131 delegates, and Clinton with 2560 delegates. Clinton would then have enough delegates to take the nomination on the first ballot.
In the end, Clinton will win the nomination on the first ballot, and she will win it with more delegates than Obama did in 2008, most likely.
Does it really makes a difference
Your not right on this one.
IfBernie was in Clinton position would he like the people to
Nominate him as the candidate for the Democratic nominee
Mrs clinton has the most votes count has the most delegates?
Conclusion I would say Bernie Sanders has the momentum
But Mrs clinton has the votes
William, good question, and I actually address it right away on the post.
Monica, one of the interesting features of this analysis is that it shoes no clear change in momentum for either candidate.
Greg,
"not caucuses but Caucasians"
But if your model accounts for minority population, at least some of the over-performance could be because minorities in those States are not participating. Which could well be the result of feeling unwelcome in the caucus situation, whereas they might show up for a primary.
Probably not that important numbers-wise, but for those looking to improve the process, a reason to eliminate the caucus.
As I have said in the past, I think primaries should be even more "closed" than they are now.
Zebra, the minorities in those states live in other states !!
"polls can be expected to be reasonable predictors of election outcomes...."
Be afraid, be very afraid. Drumpf is now tied with or even slightly leading Clinton in polls. Time to make sure your family have passports.
Who will be America's Shindler?
Greg, have you examined who would win Puerto Rico?
No, I haven't
Greg, any thoughts on why both North and South Dakota have gone to Clinton by fairly solid margins, instead of to Bernie, as you predicted?
They didn't.
See:
http://scienceblogs.com/gregladen/2016/06/08/who-won-the-california-new…